Back to Lecture Thumbnails

swkonz

jchen
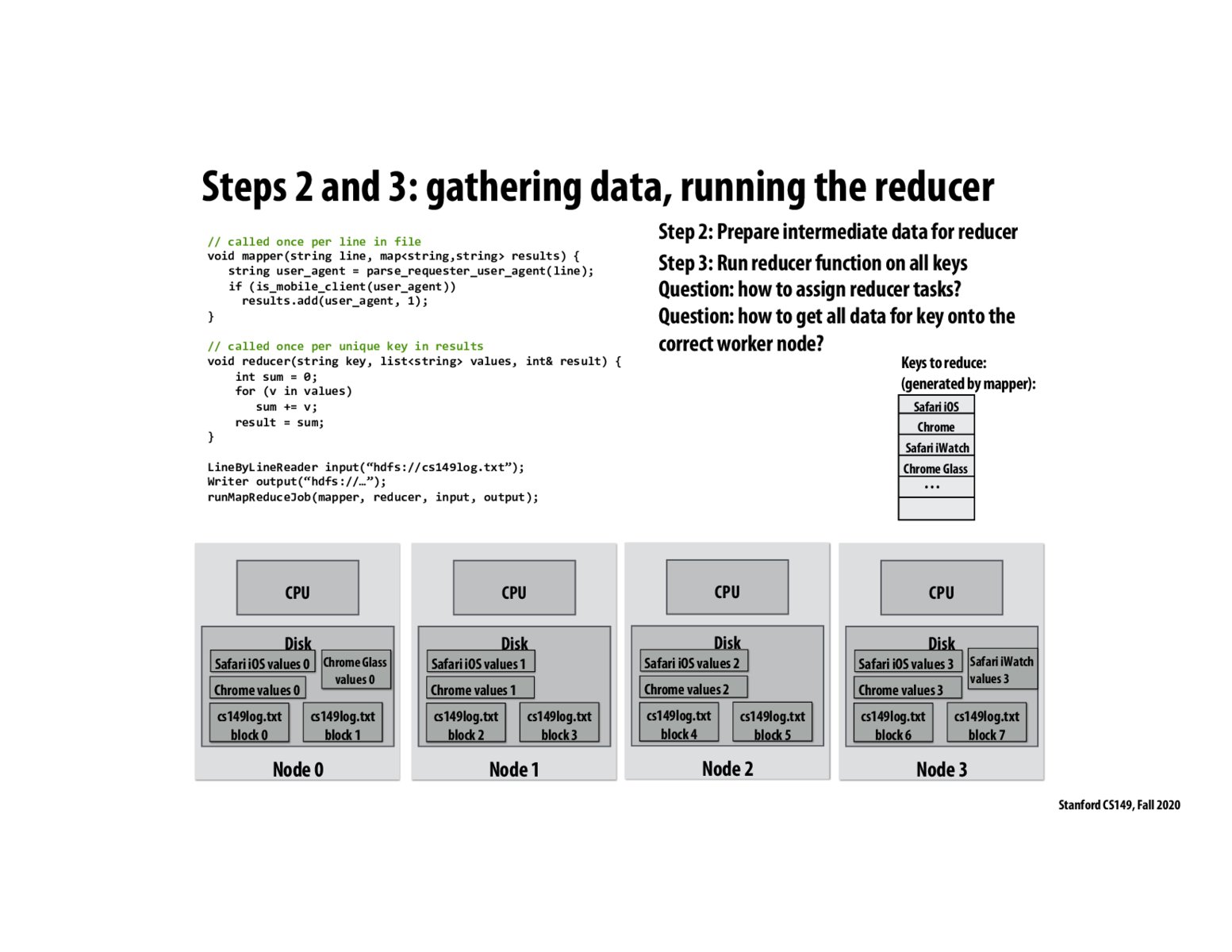
In class we talked about two main ways to assign reducer tasks. One method is to have some global job scheduler assign all values for a given key to a certain node. The other is to use some globally known hash function and assign keys to nodes based on the hashed key.
Please log in to leave a comment.
From my understanding, all the data for a particular key will be stored on a single node, and when the process needs all data at once, the data is aggregated into a single node. If the process never needs all data on a single node, then the data will remain distributed across all nodes