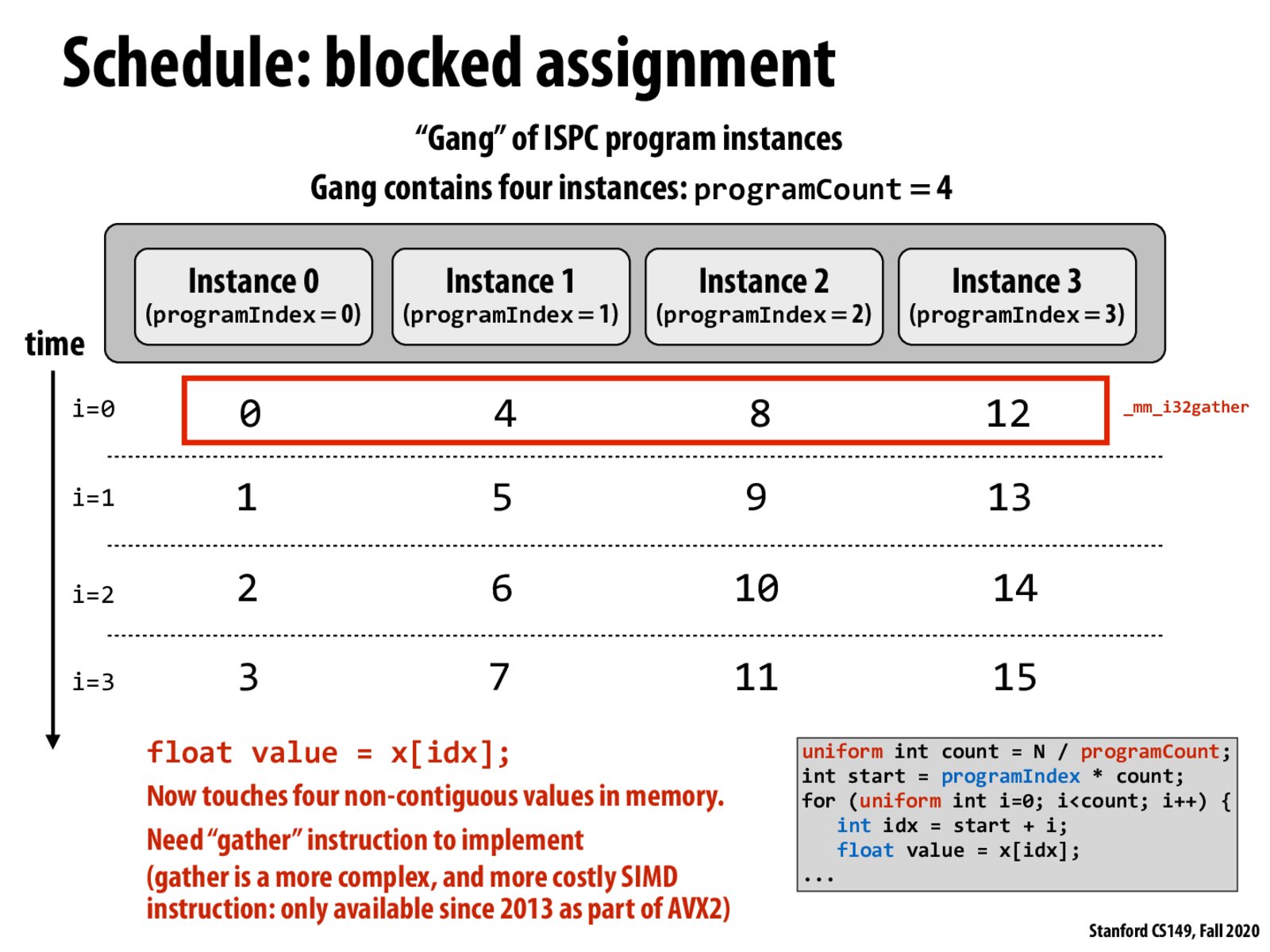


To add on, I think that another downside of the blocked assignment is that it's trickier to stuff non-contiguous data into a vector rather than moving a continuous chunk of data into a vector in a single move (as you would do with the interleaved assignment). It seems to me like you would end up having to use a lot more operations to move each piece of non-contiguous data into the vector since I'd guess you'd have to mask and move a piece of data for each instance. But I'm not 100% sure about this.

@tp I think you're right about having to issue many operations to get non-contiguous data into a vector, although it depends on how far the data is w.r.t. the vector size. It might not take a load for every single data element. Some loads could potentially bring in a few data elements if they are not spaced far apart. I'm not sure how alignment requirements would factor into this analysis, though.

This is a nice figure showing the disadvantage of block assignment. Intuitively, I thought "block assignment" means contiguous access of memory, but instead the interleaved method is a better way from the perspective of memory access. I think it also decreases cache miss?

As was described above in other comments, I find it super interesting how ISPC and it's ability to parallelize programs requires us to consider the instruction level workings and how it's actually reflected in the hardware. Without the knowledge of how SIMD works, I can definitely see why most people would consider the "blocked" assignment to be more efficient.

To reiterate why strided accesses are bad: 1. The chance of page faults increases: Consider the case when input array is very big, say 32kB. Since the SIMD width is 8, the width of the stride is 32kB / 8 = 4kB. On Linux, the default page size if 4kB. This means that the stride access crosses page size boundary. At any time, to gather all 8 elements into a vector, requires 8 pages to be resident on RAM. If one of the access page faults, it will incur a huge memory latency. What's worse is that if one of the page is on the disk, then the cost of page fault is even more expensive. It is possible that all 8 accesses incur page fault. While in the case of interleaved assignment, the maximum number of page fault is 1 per 8 accesses since if the first access page faults and the is handled, all the subsequent 7 accesses are to the same page. 2. The chance of cache misses increases The same argument applies to cache miss. It is possible that all 8 accesses to cache miss. While in the case of interleaved assignment, the maximum number of cache miss is 1 since if the first access cache misses, all the subsequent 7 accesses will cache hit

I completely agree that in a SIMD environment, interleaved assignment is better than blocked because of cache locality. Is the opposite true in a multi-core environment? In a multi-core environment, each core could be assigned a different block... OS would load/pre-fetch the whole/a large part of the contiguous block into the respective core's L1 cache which is good for cache locality. If we use an interleaved assignment in multi-core, each core's cache will contain the array which means that we are duplicating space which seems wasteful.
Please log in to leave a comment.
As was explained in lecture: On a first glance the "blocked" way seems to be more efficient because each instance accesses a contiguous area of memory. However, if we think about timing, in the "blocked" program the consecutive memories are accessed at different times while the "interleaved" program accesses them at the same time. So from a cache/memory locality perspective, interleaving is more efficient.