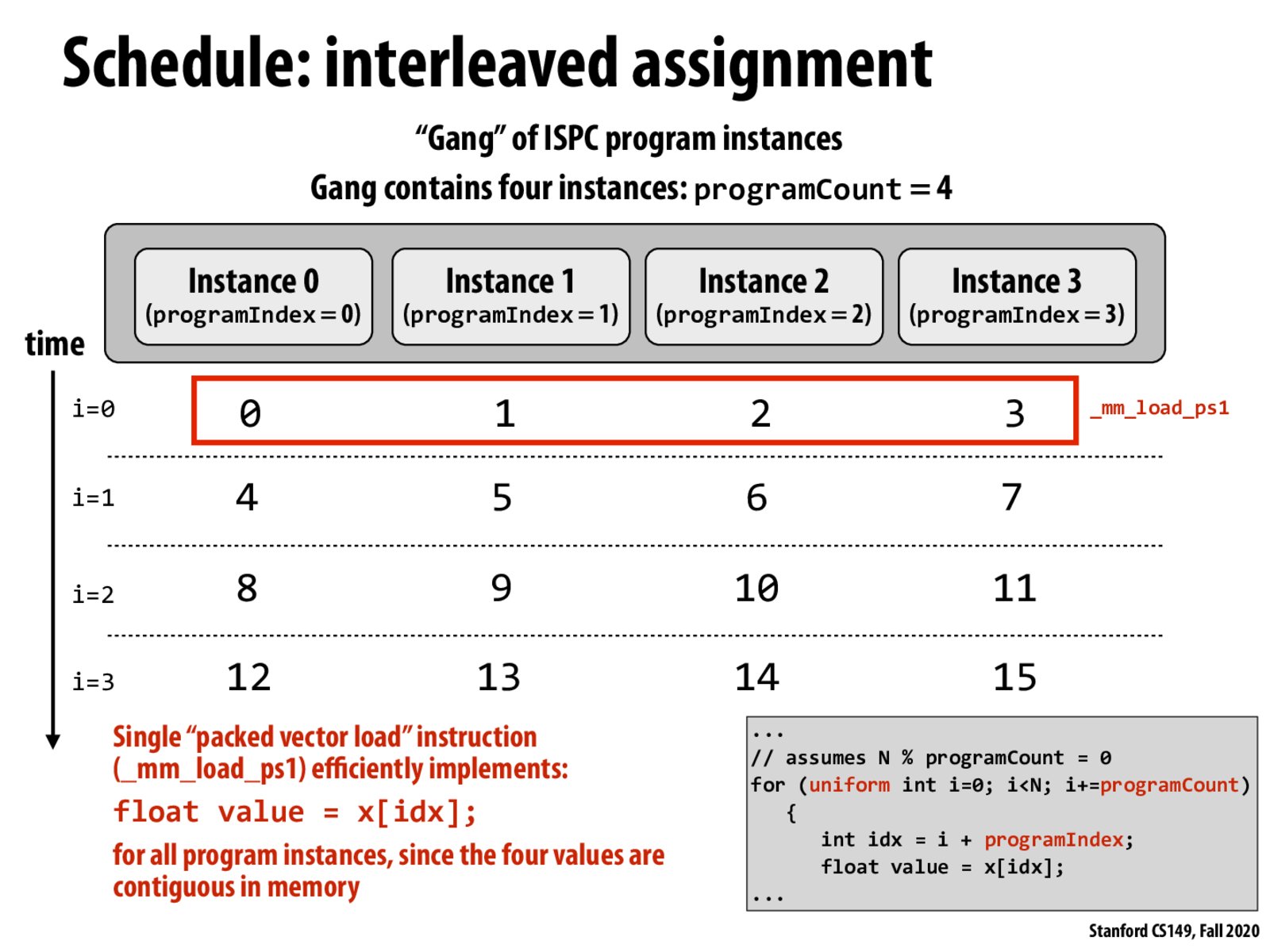


building on @rosalg:
accessing contiguous chunks of memory at the same time is faster because 1) systems can load an entire chunk of memory into a cache 2) the instances which need a certain address in memory can now look in the cache for the data at the address.
interleaving assignment amortizes the cost of fetching from memory by doing 4x the operations on that chunk of data.

@rosalg -- great post.. Just be careful about your use of "threads". This interleaved mapping of loop iterations to ISPC program instances yields contiguous memory access using packed vector instructions. Remember, that execution of all program instances in a gang gets compiled down to a single hardware thread of vector instructions.
The vector load instruction on this slide is the 4-wide SSE packed load instruction because the gang size is 4 for illustrative purposes. However, if you were running a gang of 8 instances the compiler might emit: _mm256_load_ps

@kayvonf Would it be true that if we were to use traditional multithreading to solve this problem, the blocking assignment would be better? If so, I feel like that would be a helpful slide to add for future iterations do really drill the idea that it pays to know a bit implementation beyond the abstraction. Also, some benchmarks would be really nice to make the efficiency point more visceral!

@kevtan I have the same assumptions... I think it is true because I think in ISPC cases we have all the program instances running in one single thread, so we have one cache for all the instances, and interleaved assignment in this slide will fetch contiguous chunk to cache and assign the data to all different instance, while in multithreading cases, we need to make sure that all caches in the multi-thread get contiguous chunk, so the blocking assignment would be better

@kevtan I think your point is 100% correct that if you were to implement this same code using traditional multithreading, the blocking assignment would be better because now memory access instructions would be confined to individual threads of control, and we would want those threads of control to benefit from the ability to access contiguous chunks of memory. I like your point that this is a great place where knowledge of the implementation actually ends up being an important way to conceptualize usage of the abstraction.

@kevtan @assignment7 @nickbowman love this point. I think it would be really good for this to be elaborated on/confirmed by @kayvon.

@kevtan I agree with this, and I believe this is exactly what is done in the mandelbrot.ispc in Program 3 of Assignment 1:
We launch[x] many tasks with a variable called rowsPerTask which is exactly calculating the blocking assignment in the lines
uniform int ystart = taskIndex * rowsPerTask;
uniform int yend = ystart + rowsPerTask;
Please log in to leave a comment.
I thought this part of lecture was incredibly interesting. To reiterate the main idea, we often want to access contiguous chunks of memory at the same time since that tends to be faster, so when assigning thread work, one may give, for example, one fourth of an array of numbers that are all next to one thread. This is actually causes the threads to access different chunks of memory at the same time. What's better is to interleave assignments, or to give T0 array[0] + numThreads * i, T1 array[1] + numThreads * i, and so on so that all the threads are accessing adjacent memory at the same time.