Back to Lecture Thumbnails

stanwie

xhe17
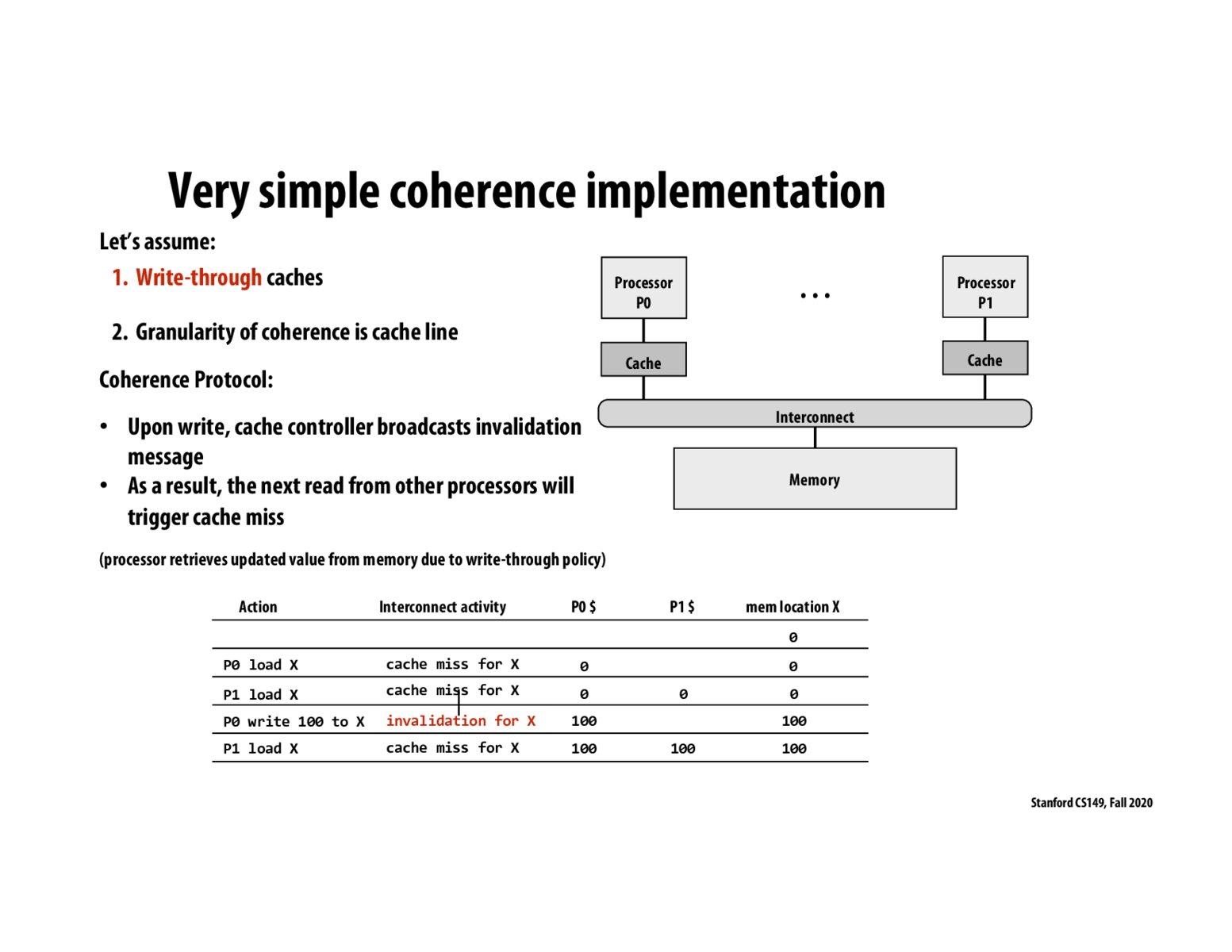
Although this implementation works. It has major flaws as it is using a write-through caches, which is less efficient compared to a write-back cache, which is also the reason we need to learn MSI and MESI protocol which is a lot more complicated compared to this design.

kevtan
From my understanding, a write-through cache is effectively only a "reading cache" as writing operations are not accelerated with the cache (they go through to main memory as well). Only read operations are accelerated when there is not a cache miss?

haiyuem
@kevtan If a processor keeps writing its own cache then the program will still be accelerated. But I agree that in general the writes (across multiple processors) are not accelerated.
Please log in to leave a comment.
From class: One thread will need to take control of the interconnect. Who ever takes control of the interconnect first gets to send their write first.