Back to Lecture Thumbnails

wooloo

Kunle
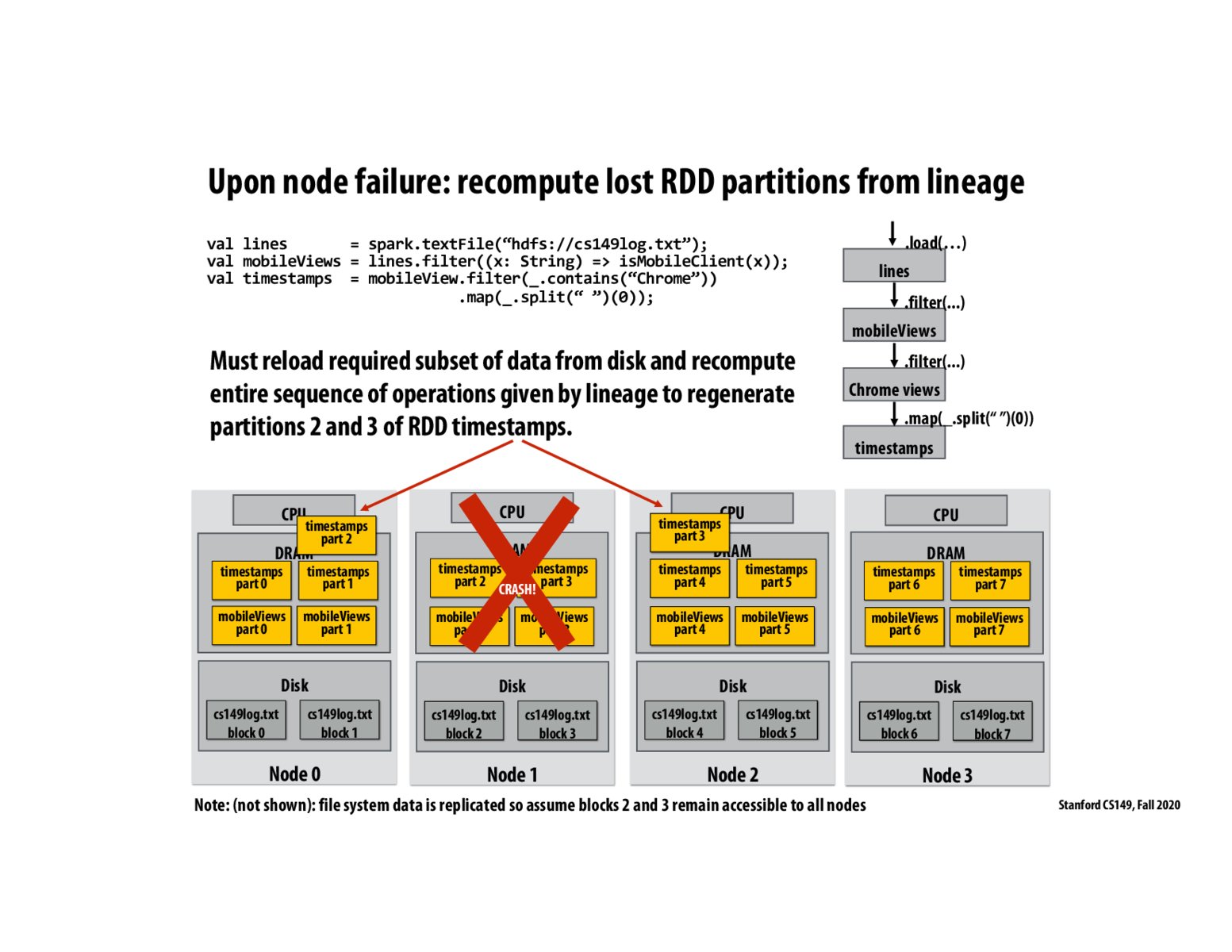
The Spark Job scheduler knows where partitions are being executed. Nodes send heartbeat messages to the job scheduler. When a node fails (no heartbeat) the job scheduler computes the missing partitions on other nodes using the lineage

blipblop
The slide states that other nodes reload required subset of data from disk and regenerate partitions 2 and 3 of timestamps, but in this example, we have to load all blocks of the complete cs149log.txt file, right? I just want to check my understanding of the program.
Kunle
You only have to reload the disk blocks that are in the dependency chain of partitions 2 and 3 which are block2 and block3 of cs149log.txt
Please log in to leave a comment.
Possibly a basic question but how do other nodes know when a node fails and which partitions were lost?