

How can we take advantage of narrow dependencies? Is this something that we can calculate live (maybe in software) or is this something that is particular to the algorithm we're computing? Or are there examples of both?

Are there situations where we unequally balance the load on machines to get cleaner dependencies like the above? Also how does this work when dependencies are dependent on branches?

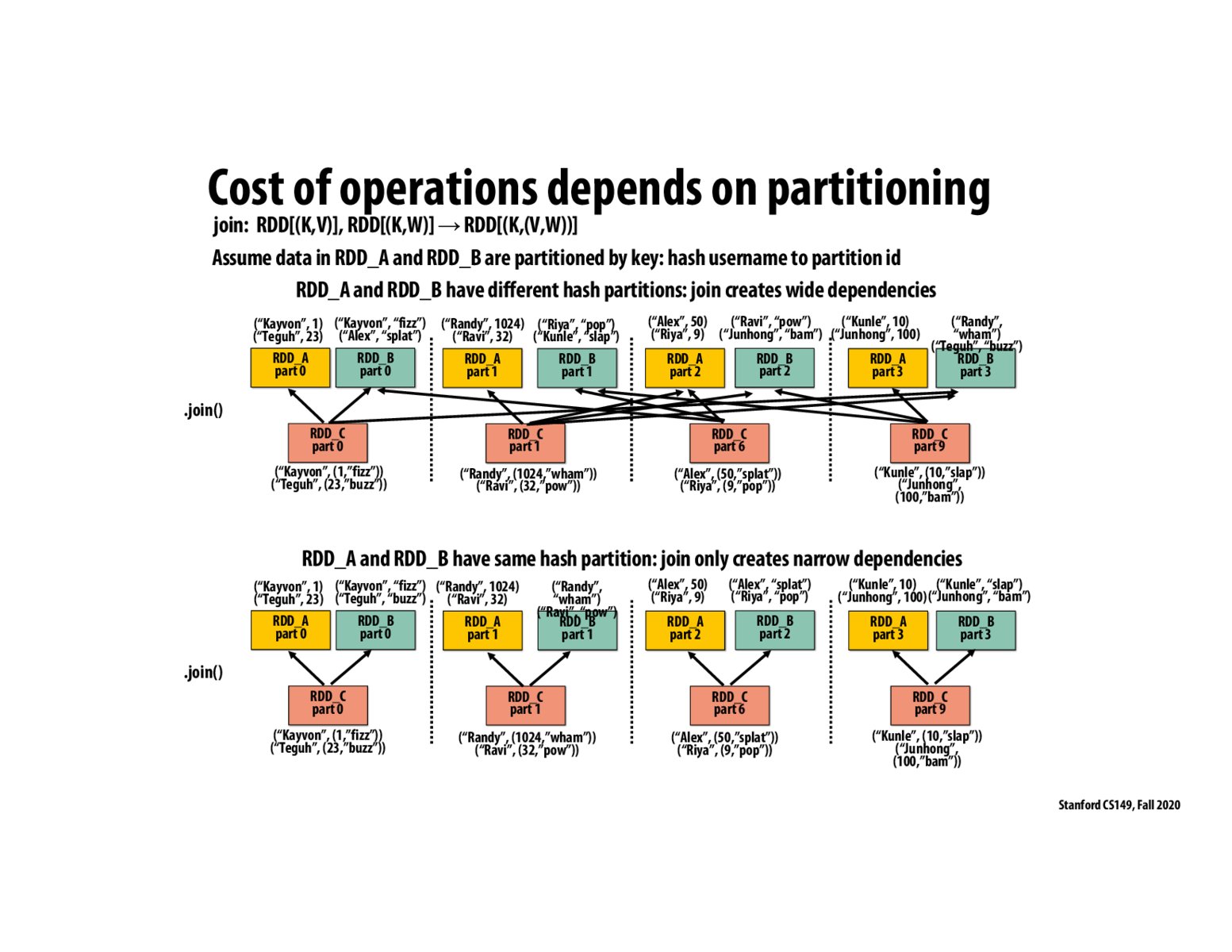
I understand narrow dependencies allow us to parallelize these threads. Computing RDD_C doesn't require computing all the RDD_A and RDD_B anymore if we have a dependencies graph as the bottom one. However, there are some operations even if we know the pattern ahead, we can't make narrow dependencies, is that correct? Like the ones we talked about in the break-out room in class.

It seems like we still need to know where to partition the data in advance and have the indexes for each key sorted before so we know which partition fits on each node. In the previous examples we used mobile client which could be an index. If we changed our indexes such as the date+time, I would assume we have to re-partition the data across the nodes.

Repeating my understanding of this slide, by partitioning our data such that only narrow dependencies exist, we can improve our resilience and runtime since RDD's don't have to wait for EVERY child RDD and can instead wait for a specific set of them.
Please log in to leave a comment.
Do we know whether dependencies will diverge or converge in advance? Or do we have to wait for the actual hash calculation to know?