

I think in this case you would have to be a little more careful with the memory access instructions in the ispc_sinx implementation to make sure that you're not trying to load memory beyond the bounds of x. However, as long as that's taken care of I think the program would still work, with just lower-than-usual vector lane utilization for the last set of vector instructions instructions to handle the last bit of the array that didn't divide nicely.

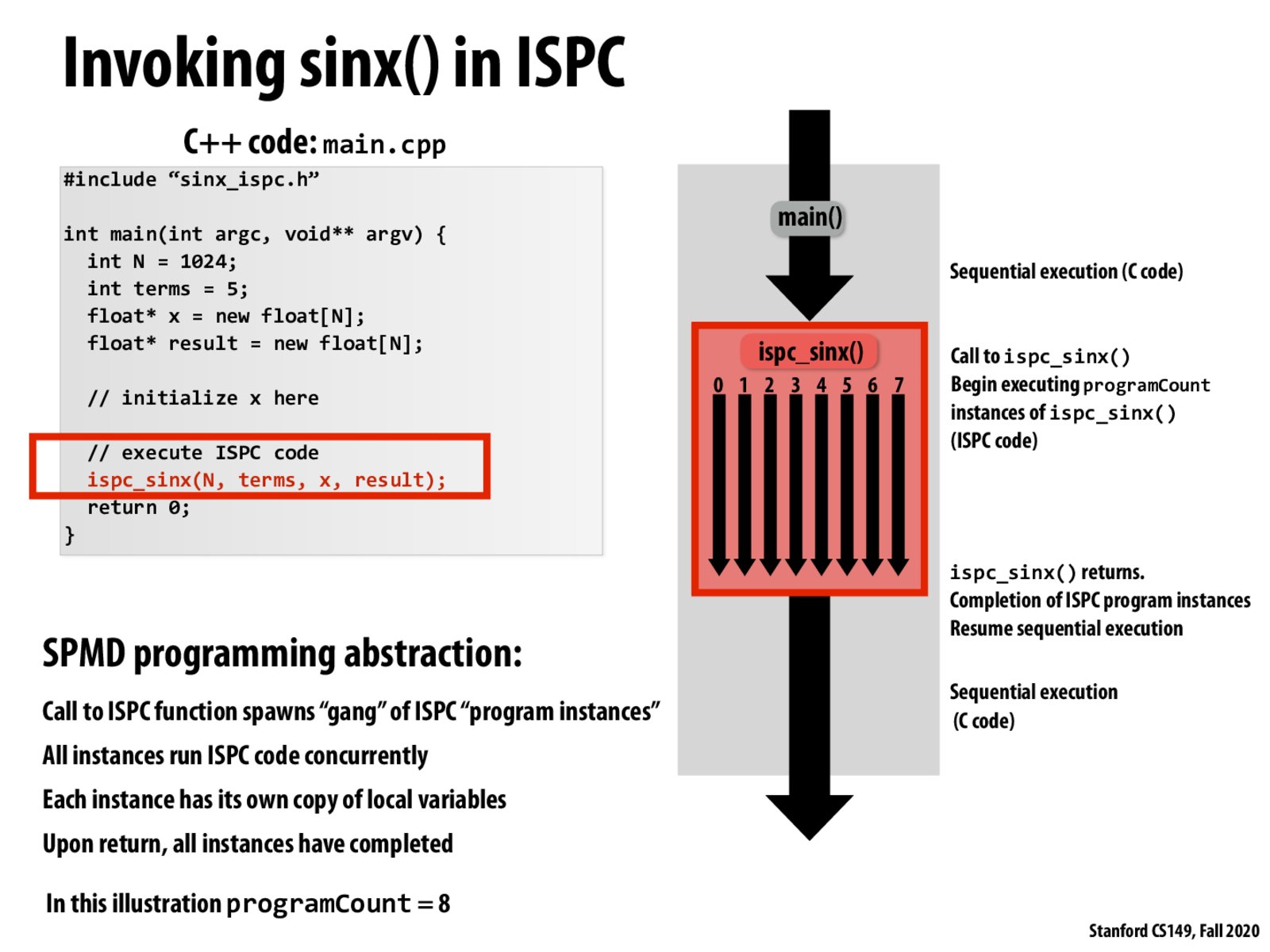
When we say for example "8-wide AVX2", the 8-wide basically means the ProgramCount=8, and it can have at most 8 independent instructions executed in parallel right?

@wanze I agree with your first statement that 8-wide means ProgramCount=8. However, they generate SIMD vector instructions so that there should be the same one instruction for all 8 instances executed in parallel.

@user1234 Agree. The instruction might still from one instruction stream but only the data parallel.
Please log in to leave a comment.
What happens when programCount doesn't exactly line up with the width of the vector instructions that the CPU supports?