

I don't think you actually need to recursive compute the partial sums. just split the work into P equal parts, compute averages over those partial sums, then sum up the P partial sums and finally divide by N^2.
Oh I see now. That makes sense. Thanks!

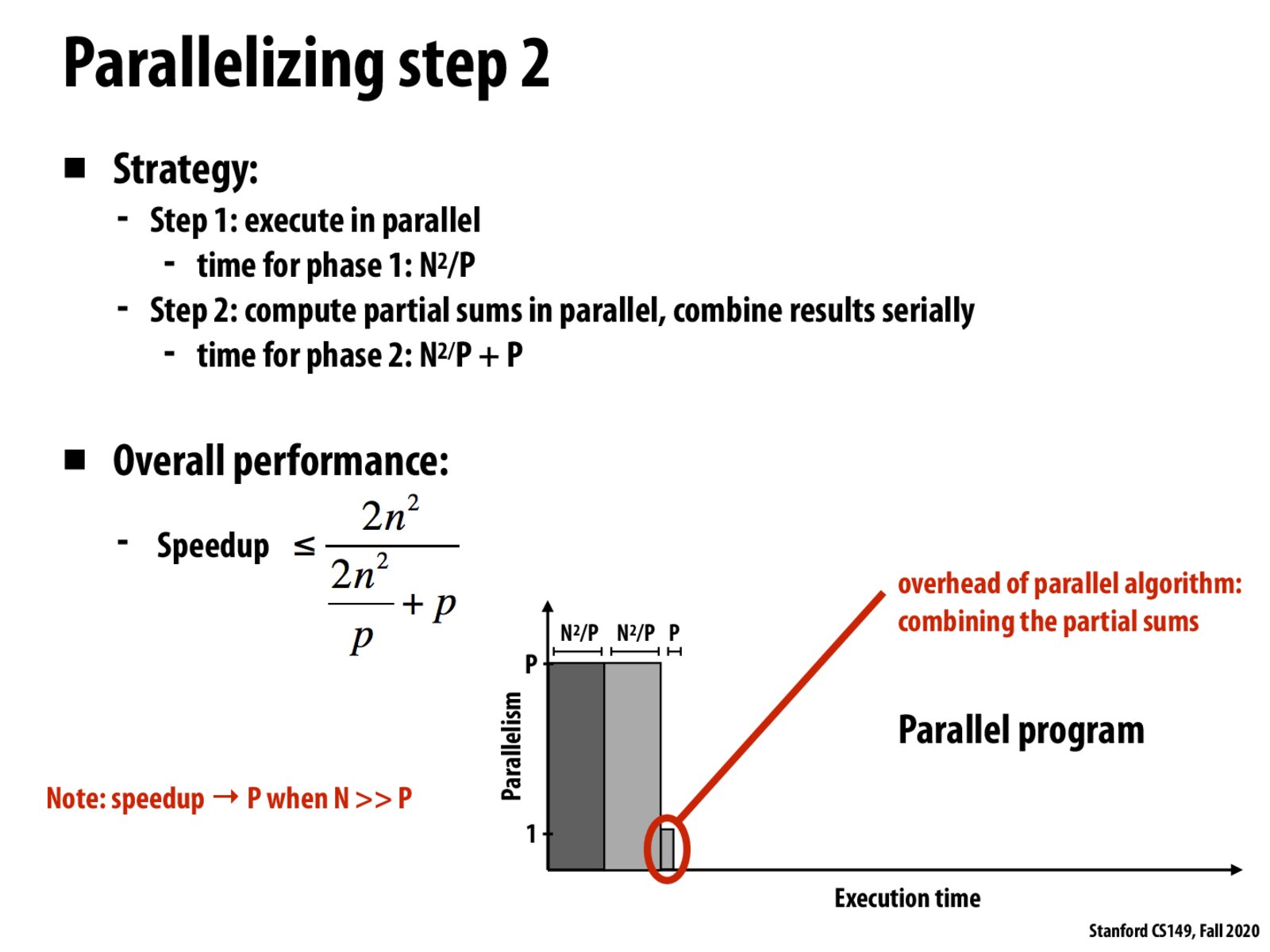
I think Chris's algorithm does make sense for very large P. Say P is on the order of N^2, then this sequential accumulation of the P partial sums is a bottleneck that essentially eliminates any speedup. It seems like there must be some inequality that tells you how many times to recurse, which in the case of P << N^2 is just 1.
And even if you only recurse once, it seems like you want to minimize N^2/P + P and use that argmin as the number of partial sums, even if you actually have more processors.

Based on the formula here, can we say that the optimal parallelism is p=O(n) in this example?

If the image can be broken up into P pieces and each processor does a convolution with a matrix of ones then writes its piece back why do we have a step combining partial sums?
Sorry, my bad its computing average of all pieces

What exactly is Amdahl's coefficient S in this case? I see how we can derive that the speedup is capped at P by taking the limit as n approached infinity, but I'm struggling to apply Amdahl's Law here.

S is the fraction of work in a program that is not parallelized. For example, because it is inherently sequential and cannot be parallelized, or because the current implementation hasn't parallelized it yet.
In this example, the latter applies. The fraction of the work that is sequential is S = P / (N^2 + P).

Hmmm one thing that I’m still curious about. While the programmer is usually responsible for decomposition, what are some cases where it’s not the programmer and the compiler can analyze the program to maximize speedup?
Please log in to leave a comment.
I feel that I'm in disagreement with the math in this slide, unless the algorithm I have in mind isn't optimal. My thought is that it would require N^2*SUM(1..log_p(N^2))[1/p^i]. For example, let N^2=256 and p=4, then you'd compute N^2/4 + N^2/4/4 + N^2/4/4/4 + ... + 1 > N^2/4 + 4. My idea is that you have to recursively compute N^2/p partial sums, then you have a new partial sum still >> p that is divided again by p. Am I incorrect in this reasoning or is there a better recursion?