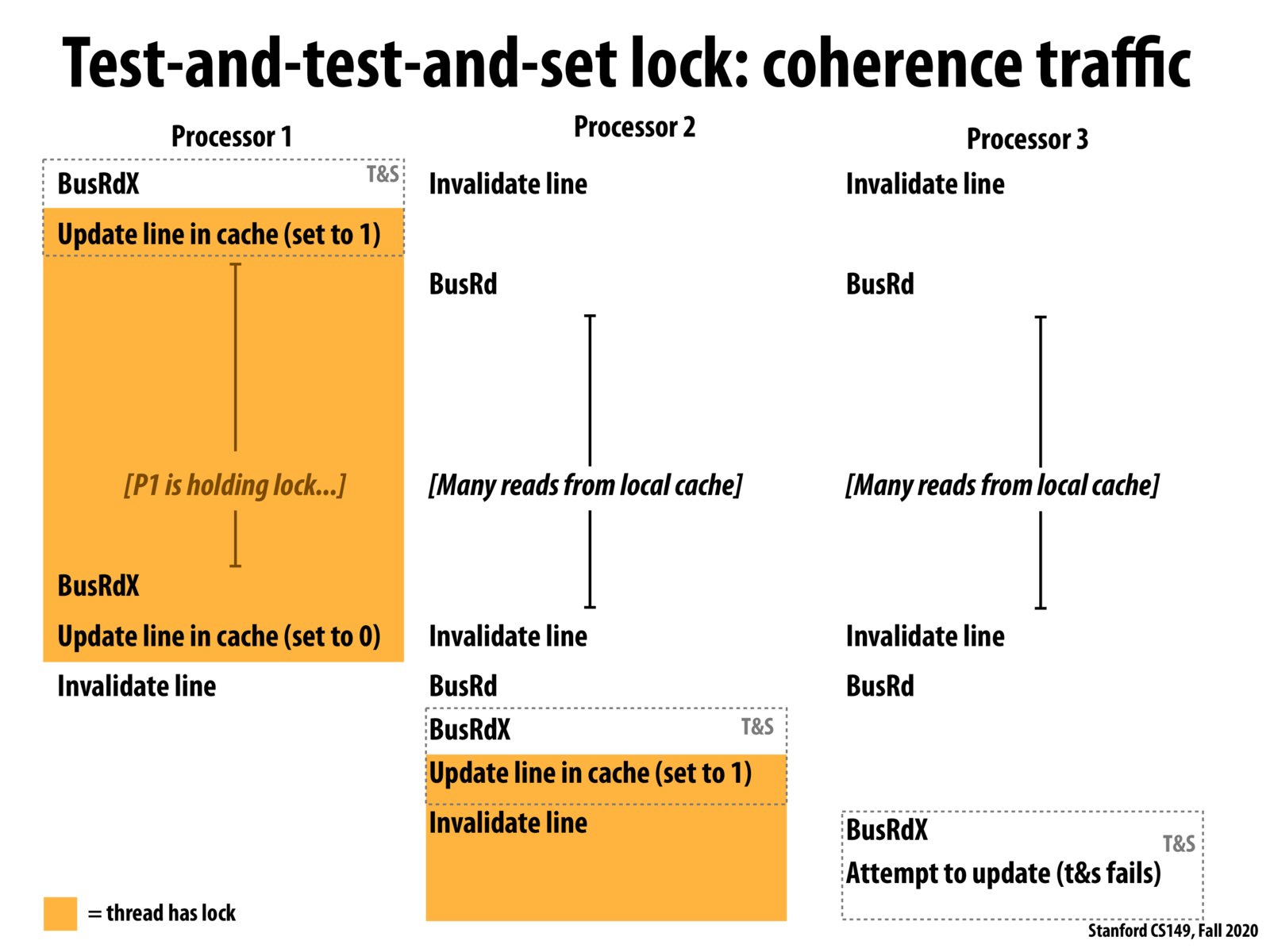


I think the reason coherence traffic is reduced is that when other processors are checking the locks, with test-and-test-and-set approach we're not doing the write (as in test-and-set), thus doesn't introduce too much cache line invalidation . Instead we only read from local cache, and don't interact with other processors.

The overhead of locks is not just from contention in that multiple threads are trying to acquire the same lock, but that there may also be significant amount of cache coherence traffic.

If cache coherence traffic affects overall performance, is it the case that too much traffic induces stalls, or something to otherwise limit throughput?

I was having trouble understanding how it was reducing the amount of traffic, because I was thinking of the cache access as mutexes, where reading would also block access, but I understood it once I realized that the cache states aren't as binary, meaning that they can access the value without any blocking by BusRd's in the S state, which are essentially cache hits that don't affect the other processors' caches' states.
Please log in to leave a comment.
With the test-and-test-and-set lock approach, there is much less traffic on the bus because processors 2 and 3 do not try to acquire the lock until processor 1 releases it. Once processor 1 releases the lock however, all the other processors attempt to acquire the lock, which still generates traffic on the bus. The ticketing approach helps reduce the traffic as it gives each processor an order in which they can acquire the lock.