

A wrap is 32 CUDA threads, but we only have ~16 computation units, that means we cannot perform the SIMD of all threads in a wrap?
Oh I just saw the 'one 32-wide SIMD operation every two clocks' in the previous slides..

So NVIDIA GPU's are even more vulnerable to inefficiency and low utilization in the case of divergent execution because it can drop to as low as 1/32 rather than only 1/8?

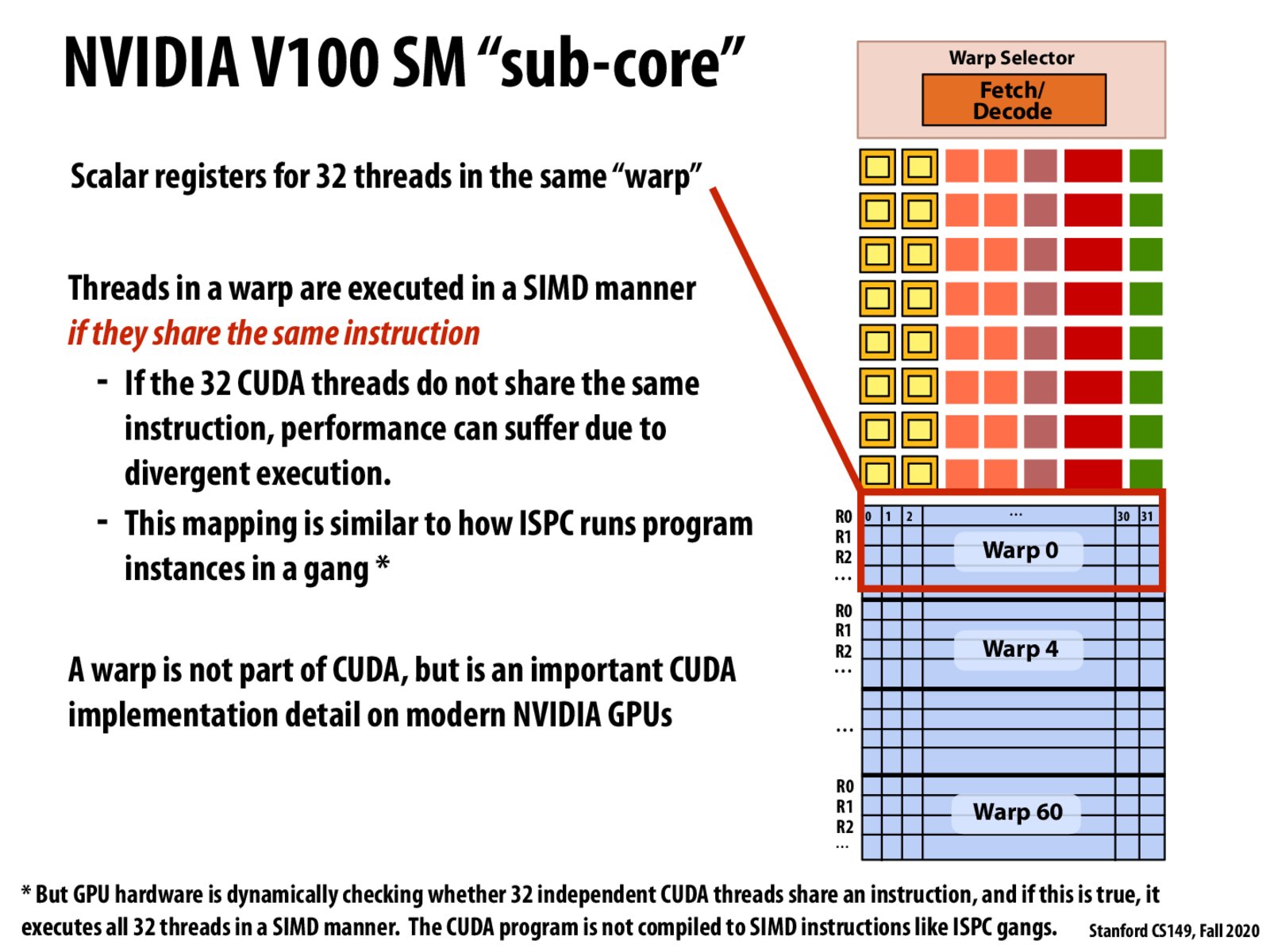
@ufxela The next slide shows the structure of the entire unit, which consists of 4 sub-cores. This might not be completely correct intuition, but I thought of it almost like an interleaved assignment of warps to thread blocks, so a thread block of 128 threads can get mapped to 4 consecutive warps across 4 different sub-cores instead of 4 warps on the same sub-core.

It's interesting that on CPUs we have to specify SIMD usage at compile time whereas in GPUs we can let the hardware figure it out at runtime. What would be the disadvantages of allowing a CPU to behave this way (especially on systems without access to highly parallel hardware like GPUs)?

@cbfariasc Yes but in most cases the amount of computation should be similar, e.g. consider a matrix multiplication or a convolution where the number of iterations is fixed. @fizzbuzz I think we also need to specify "SIMD" usage in GPUs by allocating threads.

If the threads go through same if/else branches, is this a case of sharing instructions regardless of whether the if/else condition is true or false?

Since there are 16 execution units and an add would be expected to take, say 2 cycles, is there a performance hit if two groups of 16 threads share the say instruction? Say, could 16 adds be done in one cycle and then 16 mults the next?

Say we have an if statement if (some condition) { do something...} and half of the warps go inside the if branch. Is there any scheduling mechanism to ensure that other warps will wait till those warps finish the if branch, so they will sync again after the if statement to ensure there is no divergent execution afterward?
Please log in to leave a comment.
Is there a reason why the warps in each sub-core aren't consecutively indexed?