Back to Lecture Thumbnails

potato

anon33
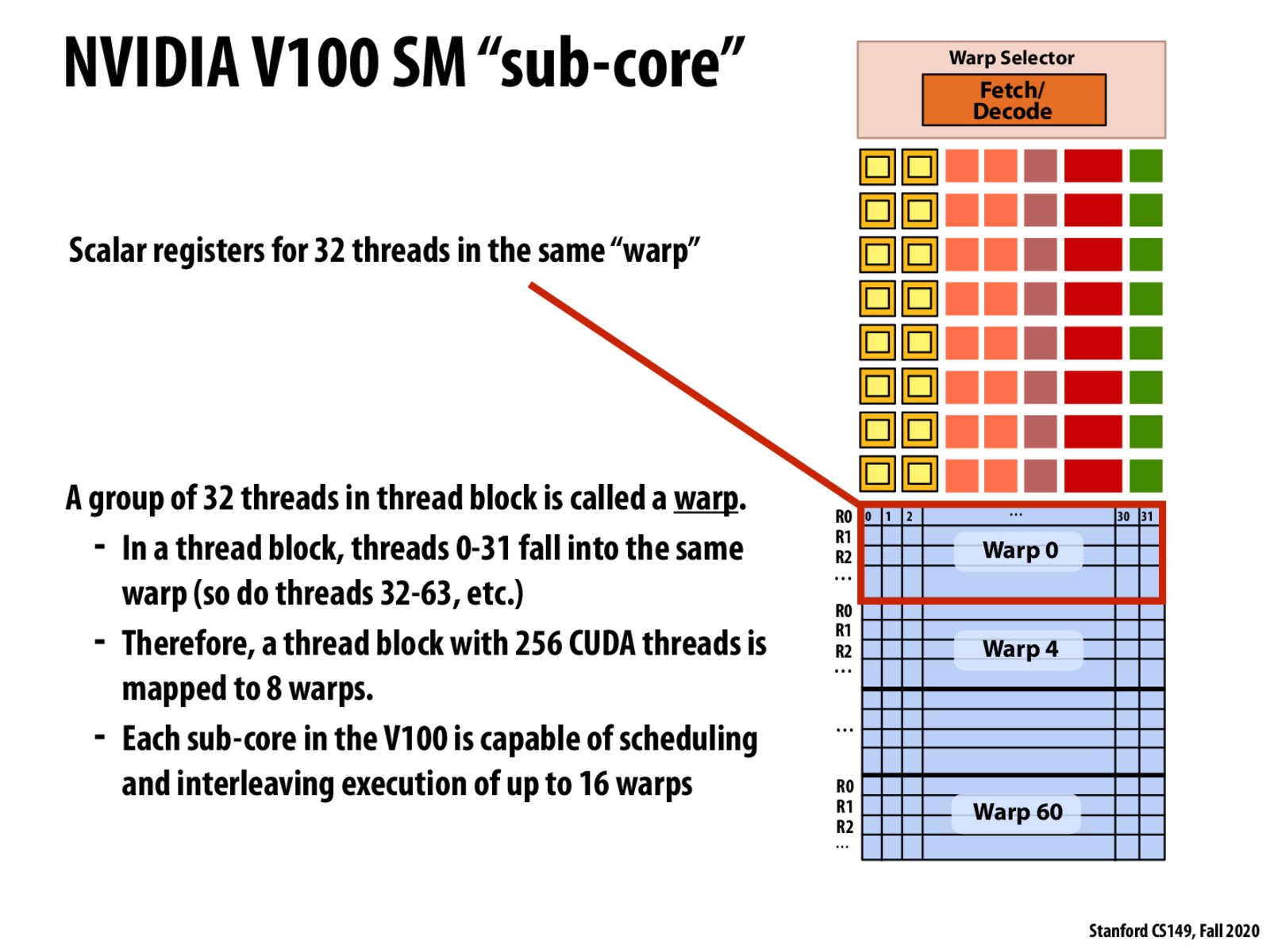
Why are there so many more interleaved hardware threads on GPU than on CPU? How does memory / cache latency compare to a CPU? It seems odd to think that of all the threads on a GPU, only 1/32 or 1/16 of them can be executing at once.

chii
When writing CUDA programs do we have direct control over mapping to warps, or is this all handled by the hardware/compiler and we can only control it via the thread block structure?

ajayram
@chii I don't know definitely but I think we don't have control in the same way we don't have control over which hardware threads are being used on a regular CPU. We let the OS decide. Equivalently on a GPU it seems like there's specialized hardware that can make these decisions for us.
Please log in to leave a comment.
A warp is equivalent to an execution context, and a group of CUDA threads is equivalent to an ISPC gang executing SIMD instructions.