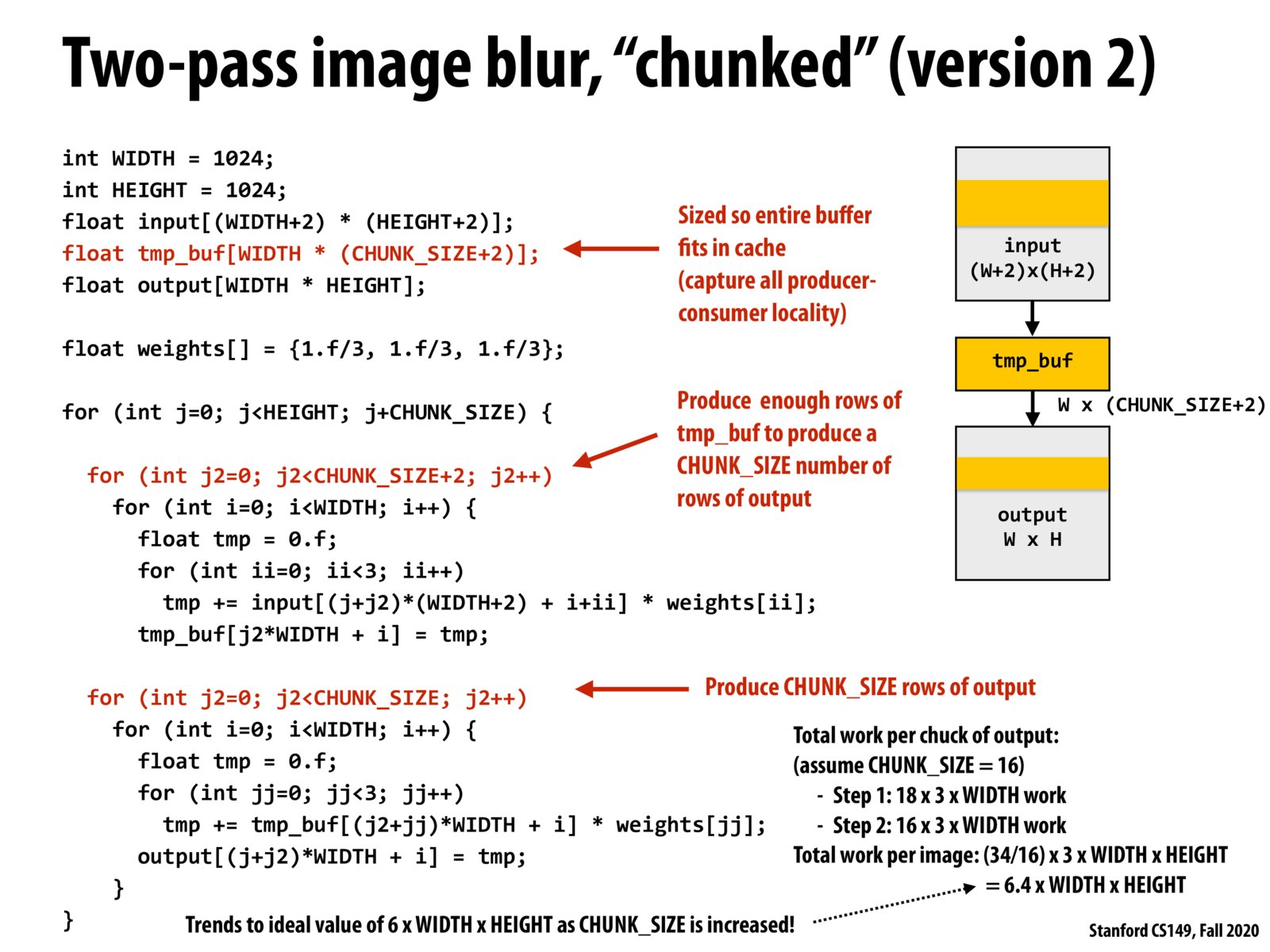


One critical part of this approach is to make CHUNK_SIZE as large as possible while still fitting into the cache.

An idea that we talked through in class was an implementation where we kept a sliding window of tmp_buf, that way we would be able to take advantage of the cache locality of already having 2 of the 3 rows required in cache. However we decided against this idea because in fact managing such a system requires quite a few additional steps, and instead we chose to create a bigger tmp_buf that we can then compute multiple rows of the final image for.

Summary for previous slides: We start from blurring an image with an 3 x 3 filter. Each output pixel needs 9 operations. For some filters, we can get the same result by performing 1-D convolution using two 1-D filters (length n), which only requires 2n operations for each pixel. However, this requires allocating a big temporary buffer which may not fit in cache and would incur bandwidth costs. Then, we consider limiting the storage size and allocating only a width x 3 temporary buffer. This buffer is likely able to fit in cache but it turns out this incurs additional operations (12 in total) for one pixel. One way to resolve this issue is to use a sliding window approach but it is more complex and not easily parallelizable. Instead, we can choose the chunk size carefully by making the temporary buffer as large as possible but also be able to fit in cache. Effectively, this approach can decrease the operations required for each output pixel and reduce the bandwidth costs as well.
Please log in to leave a comment.
This is (34/16) *3 because we are doing 34 operations per iteration of the outer j loop (per chunck).