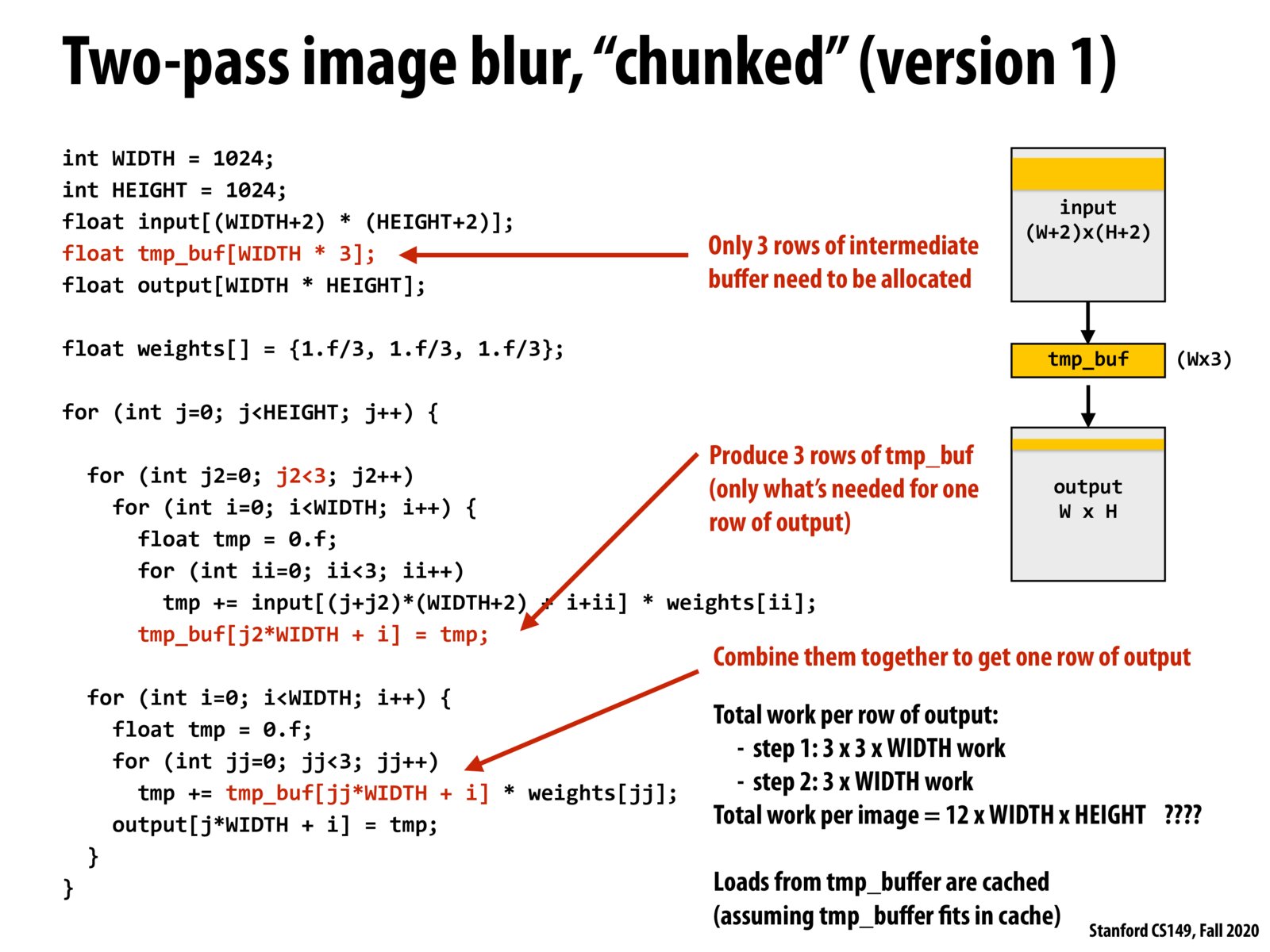

(oops ignore the above comment that was from my notes for a previous slide lol)
Summary from lecture: Instead of allocating the whole temp buffer, we only allocate three rows - this helps since we only need this info to produce a row of output. Therefore, our total runtime is now 12 operations/output pixel (which is worse than what we started with at 9 operations/pixel).
But, the main improvement is that we are allocating less space for each of our computations - they will fit in cache and now we can have a lot of cache hits as we compute down our image rows. We can do better since we are doing some re-computations of intermediate values.

Some more clarification: to produce temp, we need 9 operations per pixel, and then to produce output we need an additional 3 operations per pixel, which is how we get the total work per image as 12 ops per pixel.
Please log in to leave a comment.
By chunking the work for blurring, we now have 2N work per pixel from N^2 work per pixel.