Back to Lecture Thumbnails

tp

Drew
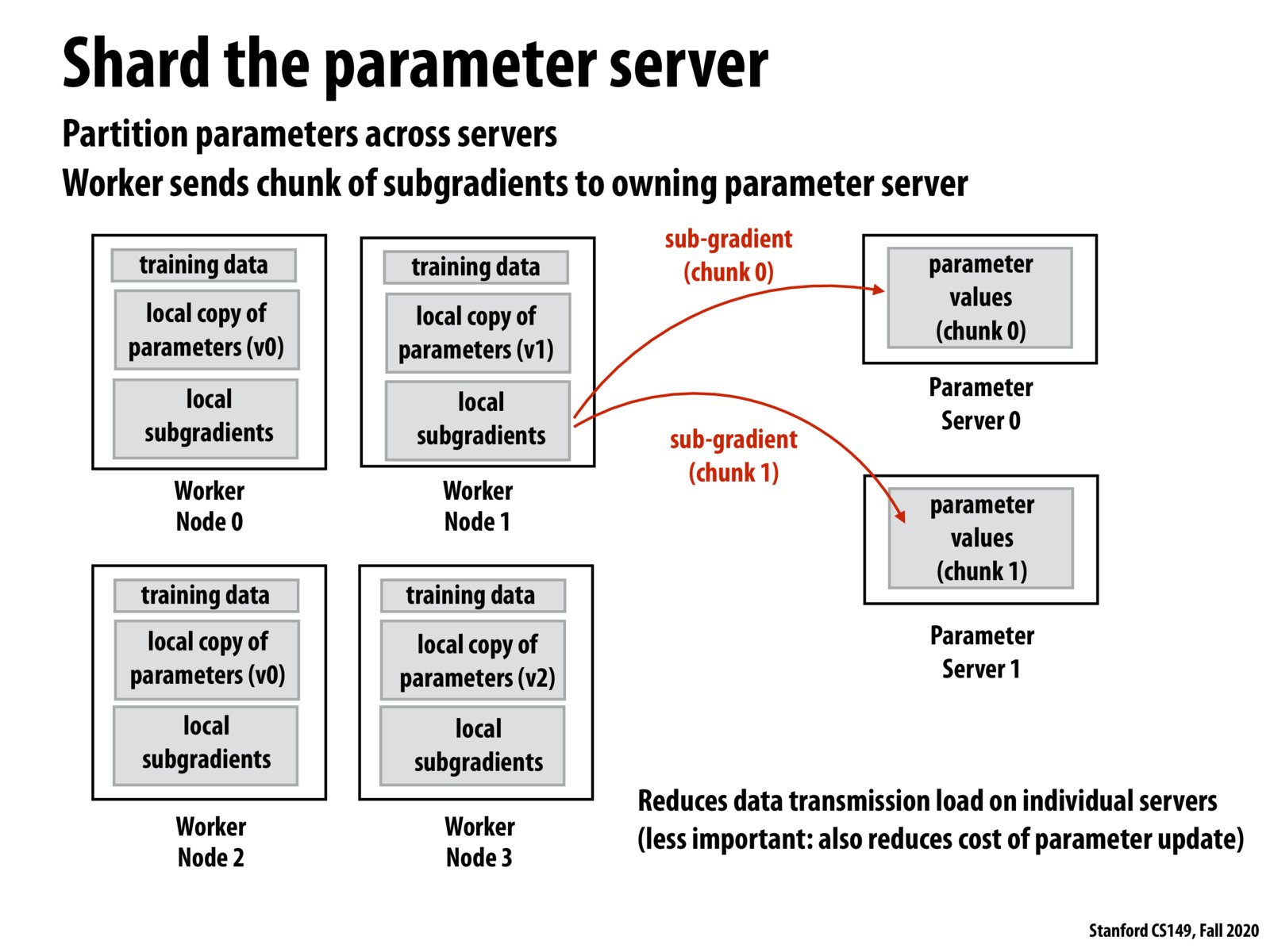
There are multiple optimizations here that reduce the amount/effect of communication required among workers and servers. First, by keeping potentially out-of-date local copies of the model parameters, workers don't need to communicate with each other directly ever. Second, by sharding the parameter "database", we can make sure the parameter servers aren't a bottleneck. However, adding optimizations to aid multi-machine parallelism often comes at the cost of reducing the algorithm to an approximation of the single-machine version. However, sometimes this is necessary if you have a model like GPT-3.
Please log in to leave a comment.
In order to reduce the bottleneck when sending and receiving parameters from the parameter server, we can split up the master parameters into shards distributed among two or more parameter servers. This way we can send and receive smaller shards of parameters from each parameter server, effectively pipelining accesses to the parameter servers.