This breakdown of training updates reminds me of Spark. How do these distributed systems handle node failure? Do they care about re-instantiating and computing loss/gradients for that data at that parameter version, or does the system simply skip that step (since we would expect the optimization process would recover given the other steps/gradients).
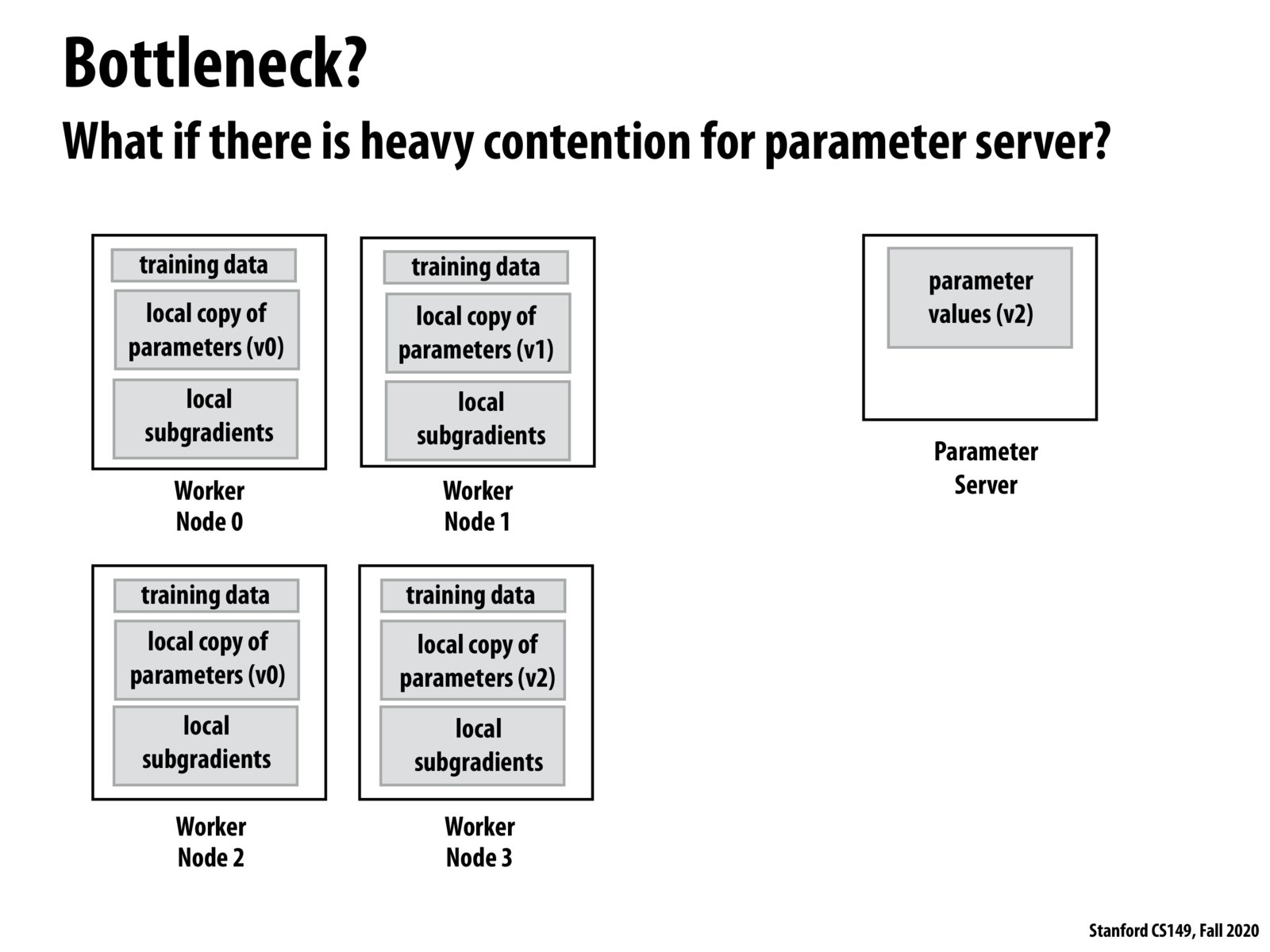

This breakdown of training updates reminds me of Spark. How do these distributed systems handle node failure? Do they care about re-instantiating and computing loss/gradients for that data at that parameter version, or does the system simply skip that step (since we would expect the optimization process would recover given the other steps/gradients).