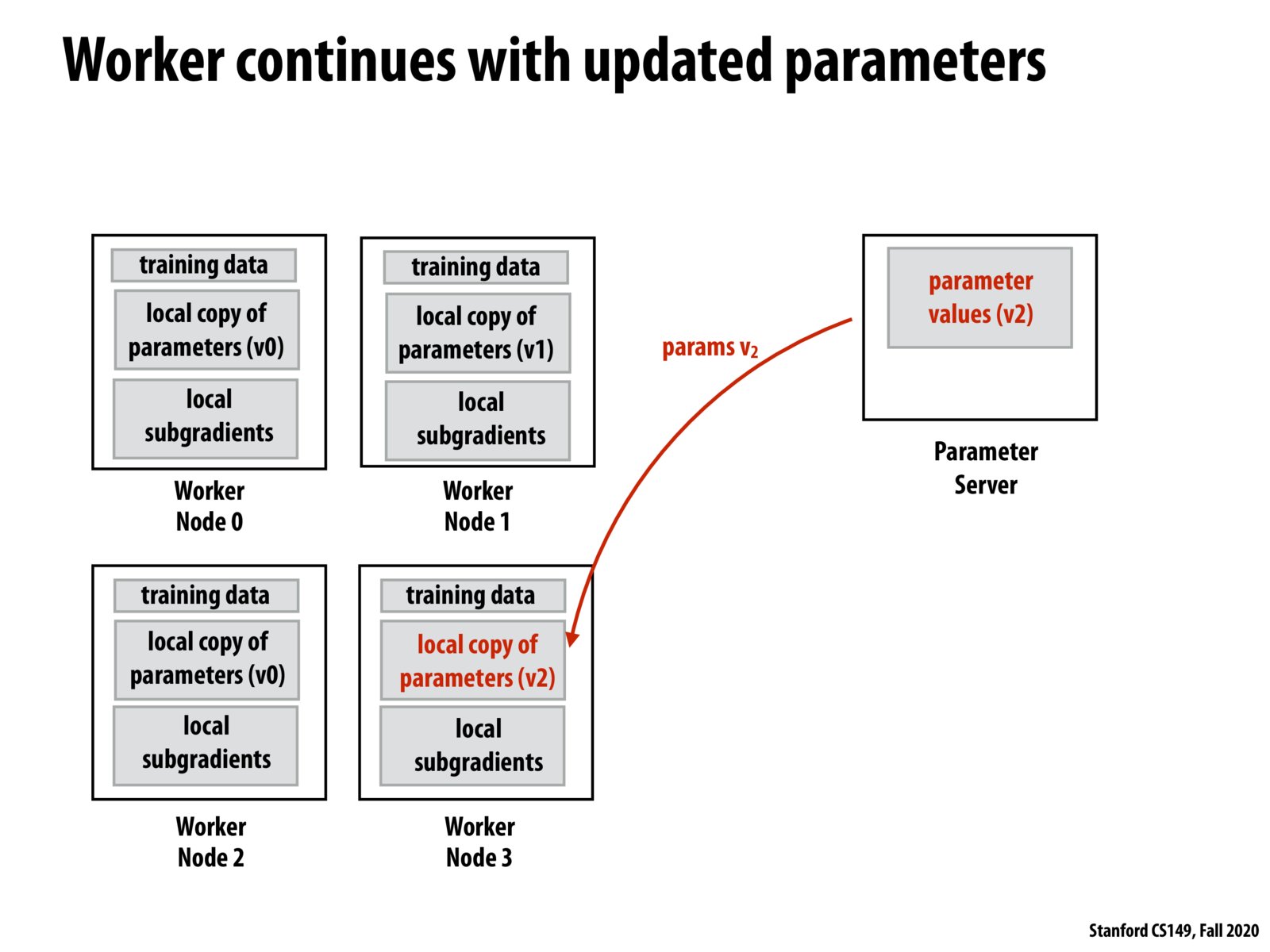


To summarize what Kayvon said in class: to compute the global gradient synchronously is to go straight down the hill in the right direction, and to compute local gradients asynchronously is to "wander down the hill": sometimes you might be getting gradients that's calculated based on old values and the direction might not be strictly the best direction, but somewhat close. This randomness is acceptable and it's better than paying the cost for synchronization.

To add on to the good comments above, it's hypothesized (though not rigorously proven) that the additional randomness in this approximated SGD can actually serve as a form of regularization for the model (i.e., it helps prevent the model from memorizing the data that it's seeing and instead look for generalizable patterns). This is empirically seen in some experiments where this distributed, approximated SGD results in a more accurate model than one trained the standard way. Of course, as @suninhouse mentioned this phenomenon is by no means well-understood.

Could this have a regularising effect on the network? Maybe the added randomness can help? I feel like it might not make too much difference because there's already so much chunking going on from the mini-batches etc...
Hahaha, just watched the next slide. Answer: other people asked the same question and found there wasn't much of an effect.
Please log in to leave a comment.
Note that how computation efficient algorithm may have implication on the SGD algorithm itself; or put another way, SGD algorithm is stochastic by itself, and approximations in such numerical methods can sometimes be acceptable. Properties of such approximation may need to be formally studied, though.