Back to Lecture Thumbnails

yayoh

yonkus
@yayoh is this a bit like stochastic modeling? As I understand it, stochastic modeling updates parameters after every training example, so this would be like batch training in a sense?
Please log in to leave a comment.
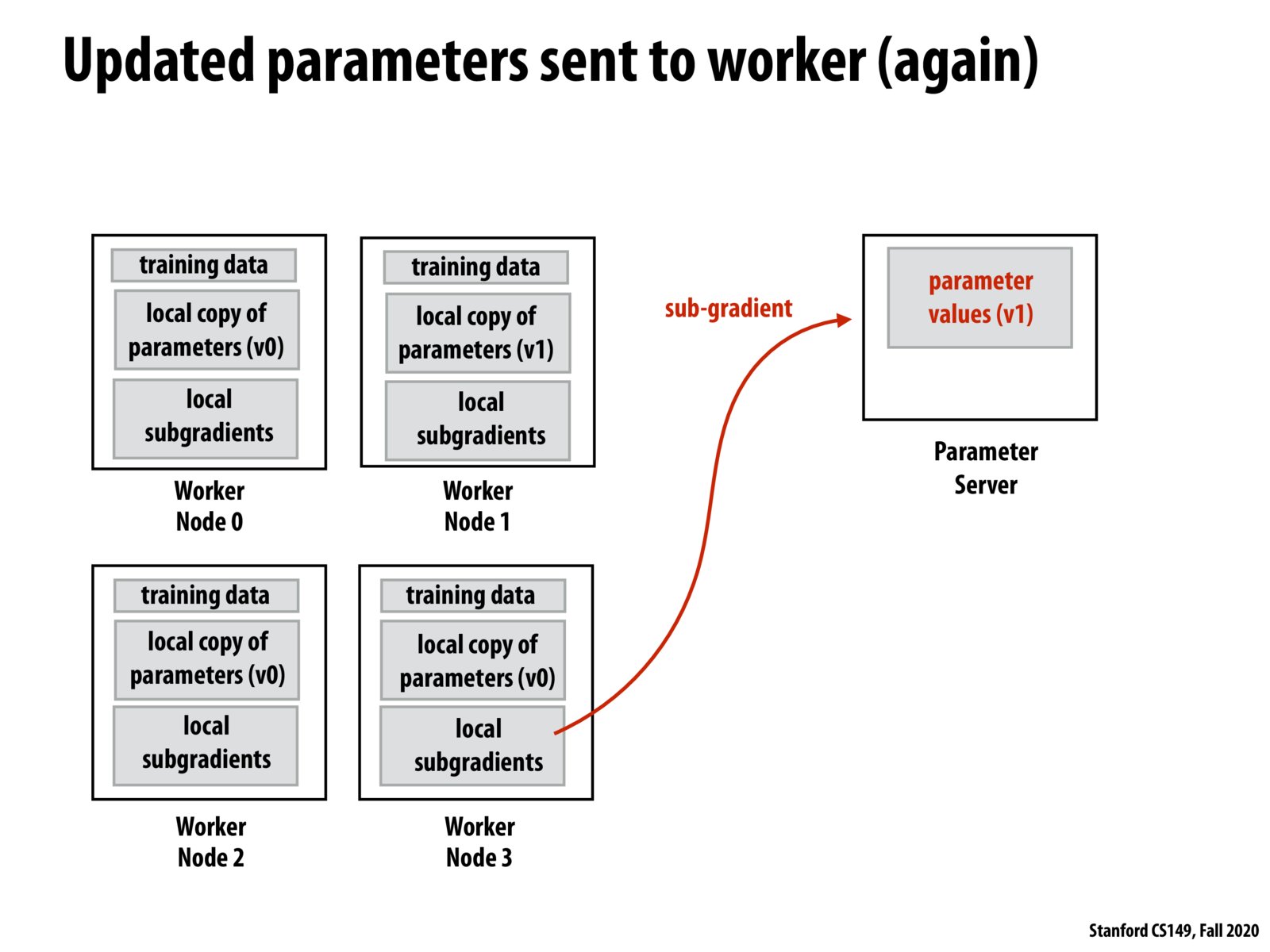
In this approach, each worker node communicates with the main node whenever it finishes its work, and then receives an updated parameter copy from the main node. This means that different nodes receive different sets of parameters from the main node, which can impact results (or the time it takes to get to the same result if GD/SGD converges)