In this architecture, we have a boss server (coordination point) "Parameter server" and 4 worker nodes. The workers operate independently and don't communicate with each other and only communicate with the Parameter server. We replicate the parameters on the worker nodes and partition the training data (usually large), so each worker only works on a partition of the data. As a result, each worker computes local subgradients.
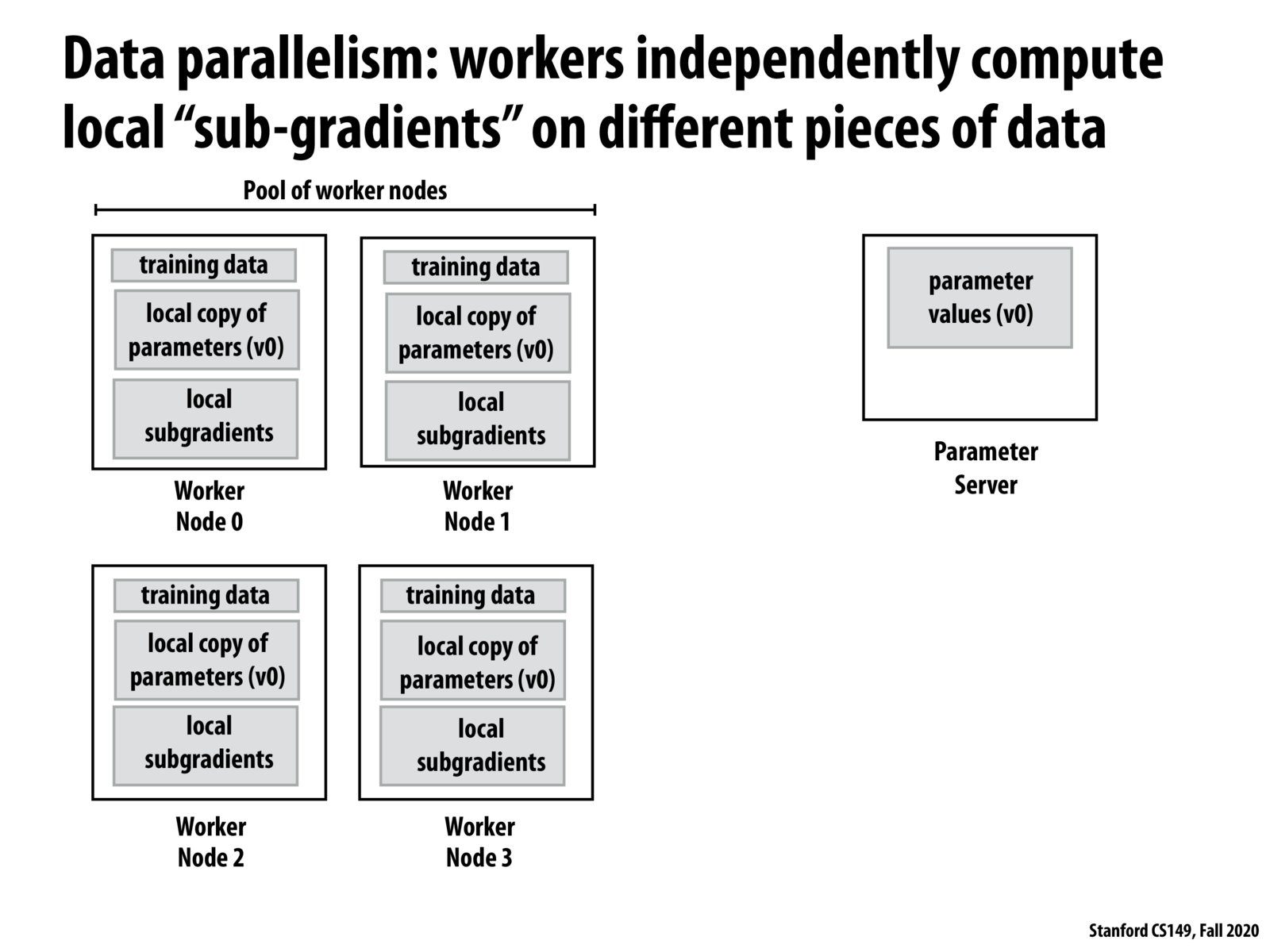

In this architecture, we have a boss server (coordination point) "Parameter server" and 4 worker nodes. The workers operate independently and don't communicate with each other and only communicate with the Parameter server. We replicate the parameters on the worker nodes and partition the training data (usually large), so each worker only works on a partition of the data. As a result, each worker computes local subgradients.