Breaking up a batch of data and distributing it to other nodes or GPUs is a common approach when training DNNs. This requires that the parameters be updated in sync with each other on the main node but distributing computation can give large speedups for training. This is such a common practice that Pytorch makes it quite easy with a special distributed data parallel package to take care of the details.
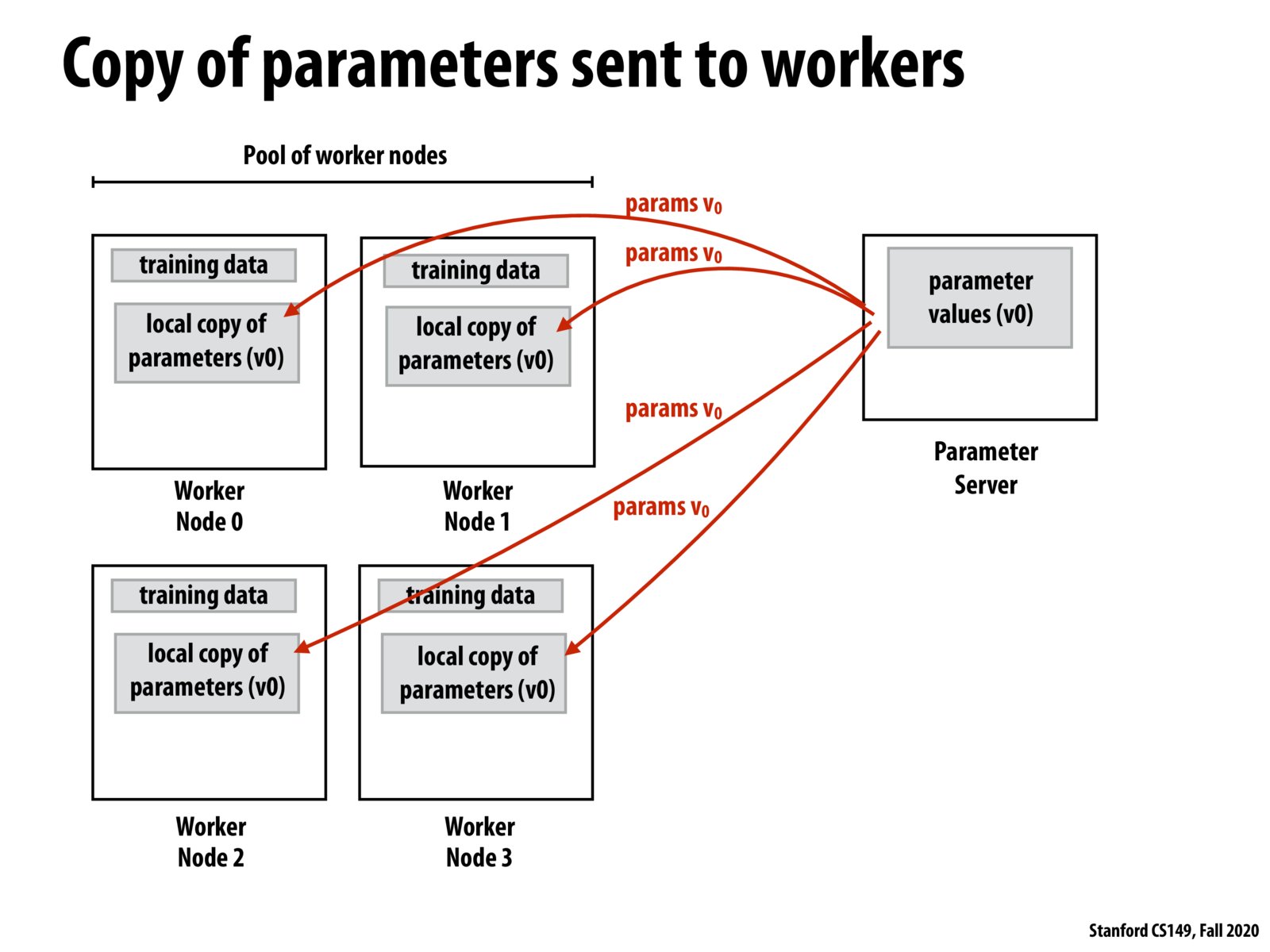

Breaking up a batch of data and distributing it to other nodes or GPUs is a common approach when training DNNs. This requires that the parameters be updated in sync with each other on the main node but distributing computation can give large speedups for training. This is such a common practice that Pytorch makes it quite easy with a special distributed data parallel package to take care of the details.