
Trying the Markdown syntax again!
- maintain list of candidate cells (beam search)
- repeat from 1 up to the max number of block
- expand candidate cells by one block
- predict their accuracies using "reward predictor"
- keep the K most promising cells
- turn the cell into a CNN, train and evaluate them
- update predictor (run iterations of SGD on new CNN and evaluation)
The markdown indentation didn't work...the last 5 bullet points should be indented :(

This architecture search idea feels very similar to meta learning for reinforcement learning. There was a paper by DeepMind a while ago where they used RL to design another network which would then learn to play various games. In this case, the the weights of the network that "learned" to play games were frozen and it used some memory / state input to facilitate the learning. In effect, instead of using backprop to learn, they learned a learning algorithm in a ML model which then was applied to small games.
I wonder if techniques developed in that sub-field may be useful to architectural search. The problem formulation is slightly different, but it seems like there's a few similarities, namely that evaluating an architecture is extremely expensive and slow (just like how evaluating a policy is slow and noisy) so there might be some interesting ideas to share with one another.
Please log in to leave a comment.
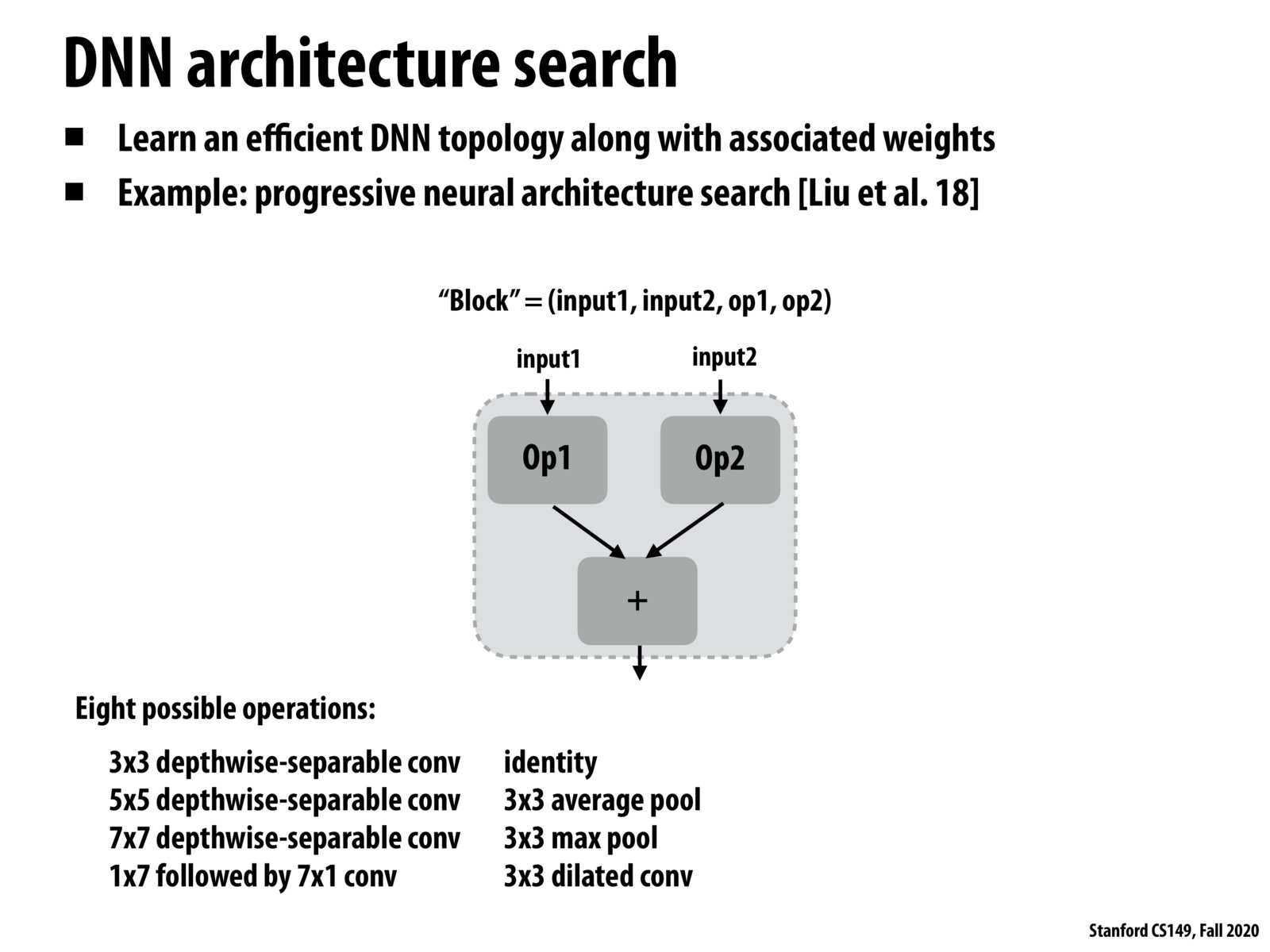
Some details about the progressive neural architecture search algorithm suggested in the paper:
maintain list of candidate cells (beam search) repeat from 1 up to the max number of block - expand candidate cells by one block - predict their accuracies using "reward predictor" - keep the K most promising cells - turn the cell into a CNN, train and evaluate them - update predictor (run iterations of SGD on new CNN and evaluation)
This part of the algorithm ensures that the neural architecture found has good accuracy. The max number of blocks parameter we set here determines how many parameters the model has and hence how efficient evaluating and training this model is - that's the CS 149 connection to the techniques discussed in the first half of lecture.
There was also a comment in class about how progressive neural architecture search feels like "machine learning in machine learning in machine learning" - here there is a predictor (the paper actually describes an ensemble model) that uses the intermediate solutions of its search to guide the search!