

I'd like to share two major benefits of convolution. One is parameter sharing. For example, a feature detector (such as a vertical edge detector) that's useful in one part of the image is probably useful in another part of the image. The other is the sparsity of connections. In each layer, each output value depends only on a small number of inputs.

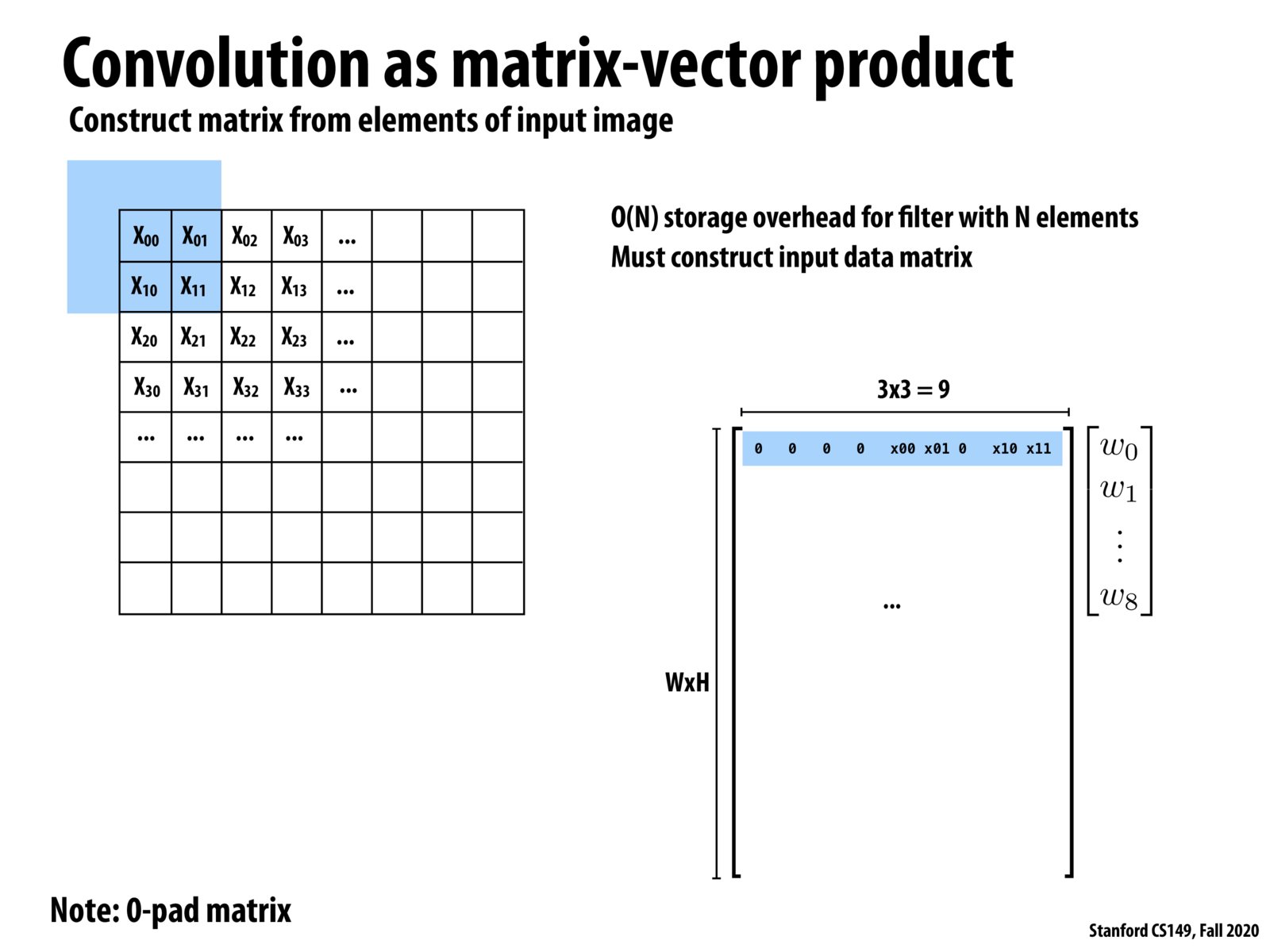
By converting the problem into matrix multiplication, this simplifies our ability to think about parallelizing it. Since we will now be thinking about a very efficient way to do the matrix multiplication. Good thing is there are already well parallelized implementations of matrix multiplication that can be reused.

Practically, convolution is converted into Toeplitz matrices using the function im2col (implementation by Caffe at https://caffe.berkeleyvision.org/tutorial/layers/im2col.html). After the convolution operation backed by matrix multiplication, the inverse function col2im is used to obtain the result in the original form.
Please log in to leave a comment.
It's a common practice to turn convolutions into matrix multiplications to use those fast, optimized matrix multiplication libraries