Back to Lecture Thumbnails

haiyuem

endofmoore
This method takes takes advantage of spatial locality by running through memory in contiguous order.
Please log in to leave a comment.
This method takes takes advantage of spatial locality by running through memory in contiguous order.
Please log in to leave a comment.
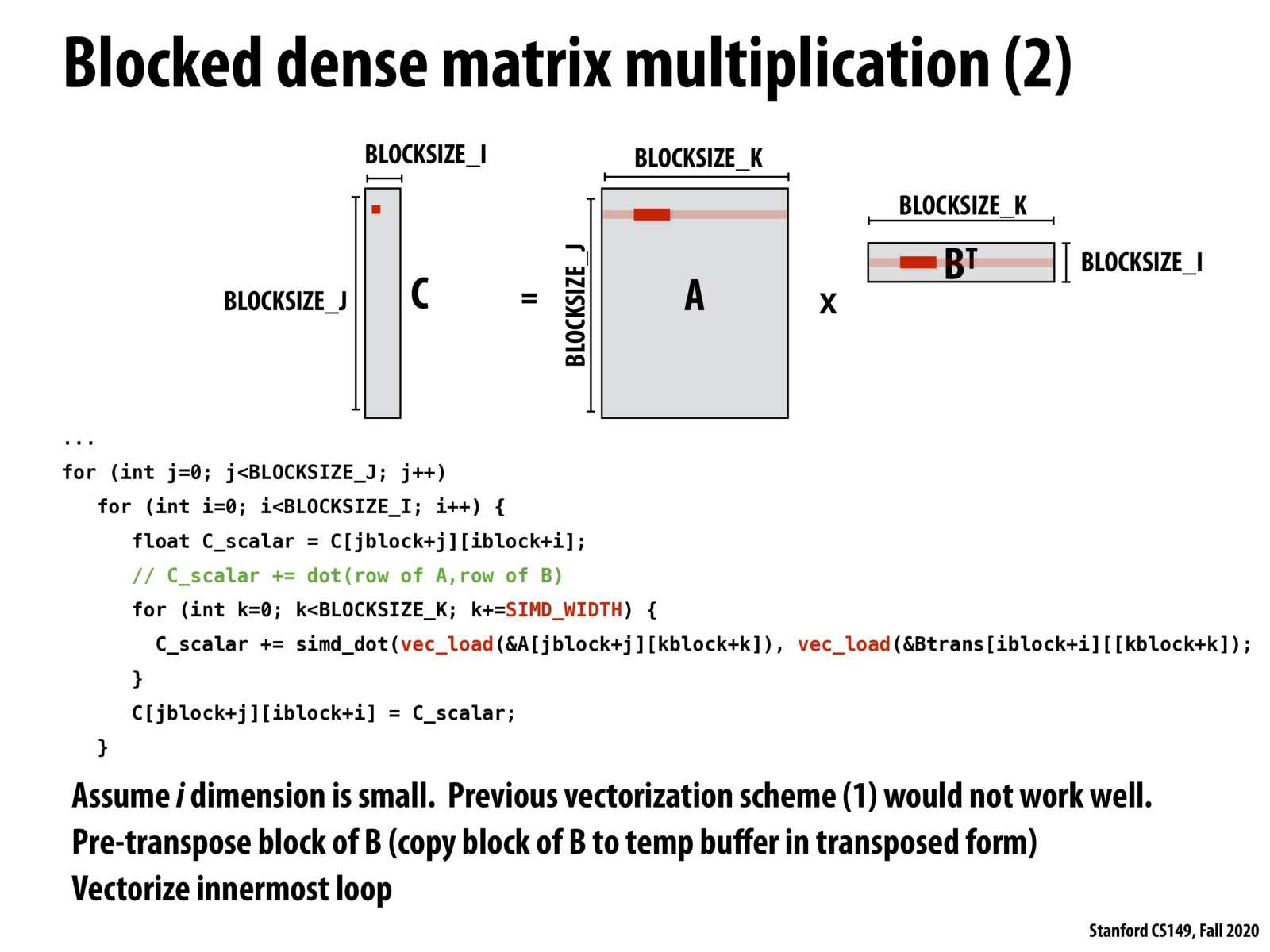
This is what NVIDIA does in GEMM calculations - most commonly transpose matrix B, but sometimes transpose A as well. It depends on how the matrices are stored in memory: row-major or column-major.