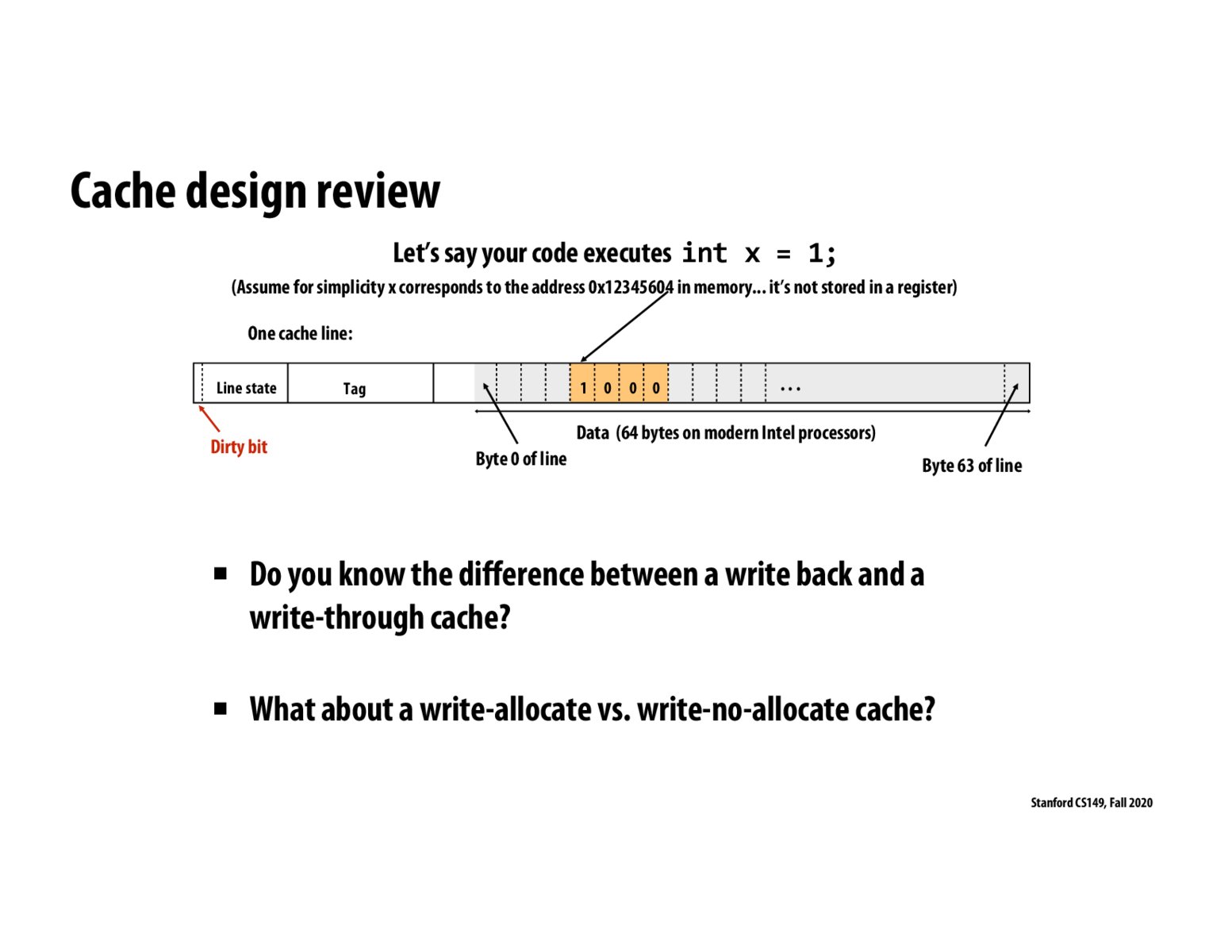


The difference between a write back and a write through cache is that the write through immediately updates main memory whereas with write-back, the up-to-date data stays in a processor cache after a write and is periodically written back to main memory.

Write-allocate vs. write-no-allocate policies are for cache misses. Write-allocate means that the block is loaded into the cache after a write miss, while write-no-allocate means that the block is modified directly in main memory and is not loaded into the cache.

I think I missed some part of the lecture about the "Tag" in the cache line... What information does the tag store? Does it store the data's address in the main memory? (Then I think the size of tag should be log2(memory slots))
@assignment7 For a direct-mapped cache, an address is implicitly divided into Tag, Index, Offset fields, where the Index determines which row in the cache the address maps to, and Offset determines the offset within that row. The Tag is the remaining bits, and is used to uniquely identify the address.
During a lookup, even if the row corresponding to the address' Index is filled, the cache needs to check if the Tags match, since multiple addresses can map to the same Index.
@potato get it. Thank you!

It was mentioned in lecture that write-through caching is quite slow because we need to write to main memory at the same time as each write to the cache, which is why we'd rather have a cache coherence protocol that works with write-back caches. I believe this better protocol would also use write-allocate for the same reason.

The (byte addressable) memory address is split into a few components for caching: tag, index, and offset.
The offset "field" is the byte offset within the cache line's data. If the cache line is 4 bytes: the offset will be 2 bits, 8 bytes: 3 bits, 64 bytes: 6 bits, etc...
The index "field" accesses the cache. In a direct mapped cache, this will just access a cache line as @potato mentioned above. In a N-way set associative cache, this will access N cache lines, or one set. If the depth of a direct mapped cache is 256 cache lines or the number of sets in an associative cache is 256: the index will be 8 bits, 512: 9 bits, etc...
The tag is what uniquely identifies the address, and as @potato mentioned is just the remaining set of bits in the address. In a direct mapped cache lookup, we check the cache line's tag and valid bit. In a N-way associative cache lookup, we check N cache lines' tags and valid bits.

@assignment7 and @potato, I was also having trouble trying to wrap my head around what the Tag section actually was and found these 2 videos incredibly helpful (he also goes into great detail to explain set associative caches): Direct Mapping, Set Associate Mapping

My understanding of the cache types:
A write-back cache means that writes only modify cache lines (setting dirty bits as needed, and NOT writing to memory). A write-through cache means that writes always write to memory (meaning dirty bits are not needed).
A write-allocate cache means that upon a write-miss, the relevant data is loaded from memory into the cache and further writes will operate on the cached data. A write-no-allocate cache means that upon a write-miss, the write occurs on the data in main memory with no loading to cache. Note that this means that lines are only loaded to the cache on read misses.
Write-back caches and write-allocate caches go hand-in-hand since both aim to perform writes on cache lines whenever possible rather than on memory.
Conversely, write-through and write-no-allocate caches work well together for the opposite reason.

Is direct mapped cache just a special term for a 1 way set associative cache?
@ufxela yes!

I'm a little confused about the explanation of tags and line offsets. I understand that the memory addresses are 32-bits in this example and the cache line is 64B, so the line offset can be represented in 6 bits, but I'm still not sure what exactly the tag is representing. Is the tag just the upper 26 bits of the address while the line offset is the lower 6 bits?

Right, yeah - the tag is essentially allowing us to convert between the main memory space and the cache memory space.

Write back caches use write allocate because later if we write again it will be a hit and we can avoid fetch from memory. Write through caches use write no allocate since future writes will still need to go to memory.

The write-allocate and write-no-allocate are really here to differentiate when we decide to load data into CACHE when R miss and W miss.
Write-allocate: load data into cache on both R/W miss Write-no-allocate: load data into cache ONLY on R miss
The Write Back and Write Through are to differentiate when we copy data to MEMORY.
Write Back: Copy to memory at a later time, so cache has up-to-date info. Write Through: Copy to memory whenever W happens, so memory AND cache both have up-to-date info.
Note: With write through, there is no speed up benefit for W, but it still provide faster access for R.
Please log in to leave a comment.
From lecture - Write back works best with a write allocate cache and a write-through cache works best with a write-no-allocate cache.