

This is also similar to one of the scenarios in the Task scheduler homework where single thread performed better than threadpool for a particular workload. Cost of setting up and managing work in parallel execution, e.g. threadpool, cluster etc. isn't always cheap, so we must have a large enough computation, in this case TB/PB scale data, such that the management cost incurred becomes insignificant compared to the computation cost.

Are there certain workloads on which single-threaded approaches will outperform distributed algorithms in any circumstance and if so how do we distinguish these cases?

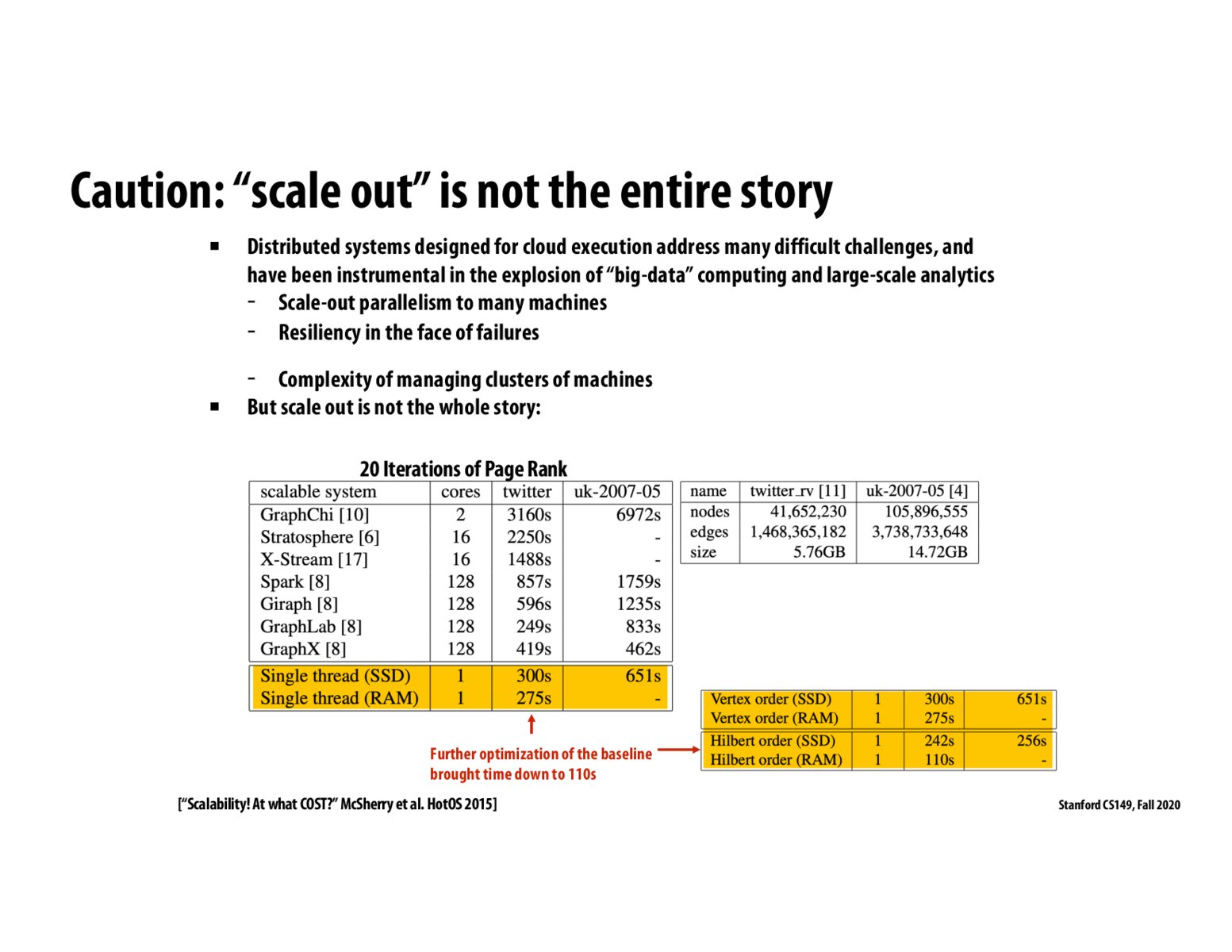
The broader point in this slide, and the COST paper (btw, a highly recommended read), is that scalability is not the full story. Often we just want to run fast, so if well-written code can get high performance on one machine, that's a lot more convenience than having to use an entire cluster.
Starting with very slow code, and then parallelizing that slow code to use many machines to get high throughput (and inventing systems to make it easier to use many machines) is a little silly when an alternative solution to getting the same or even higher performance is to just improve the performance of the single-threaded code.
In other words, often it's smart to have a good piece of single-threaded code before you start thinking about wide scale out.
Please log in to leave a comment.
We need to make sure we are actually operating on large amounts of data in order to make use of Spark efficiently, otherwise there is too much overhead. If the entire dataset already fits in memory on a single node, might as well just use that single one rather than managing a whole cluster of nodes.