Back to Lecture Thumbnails

wzz

haiyuem
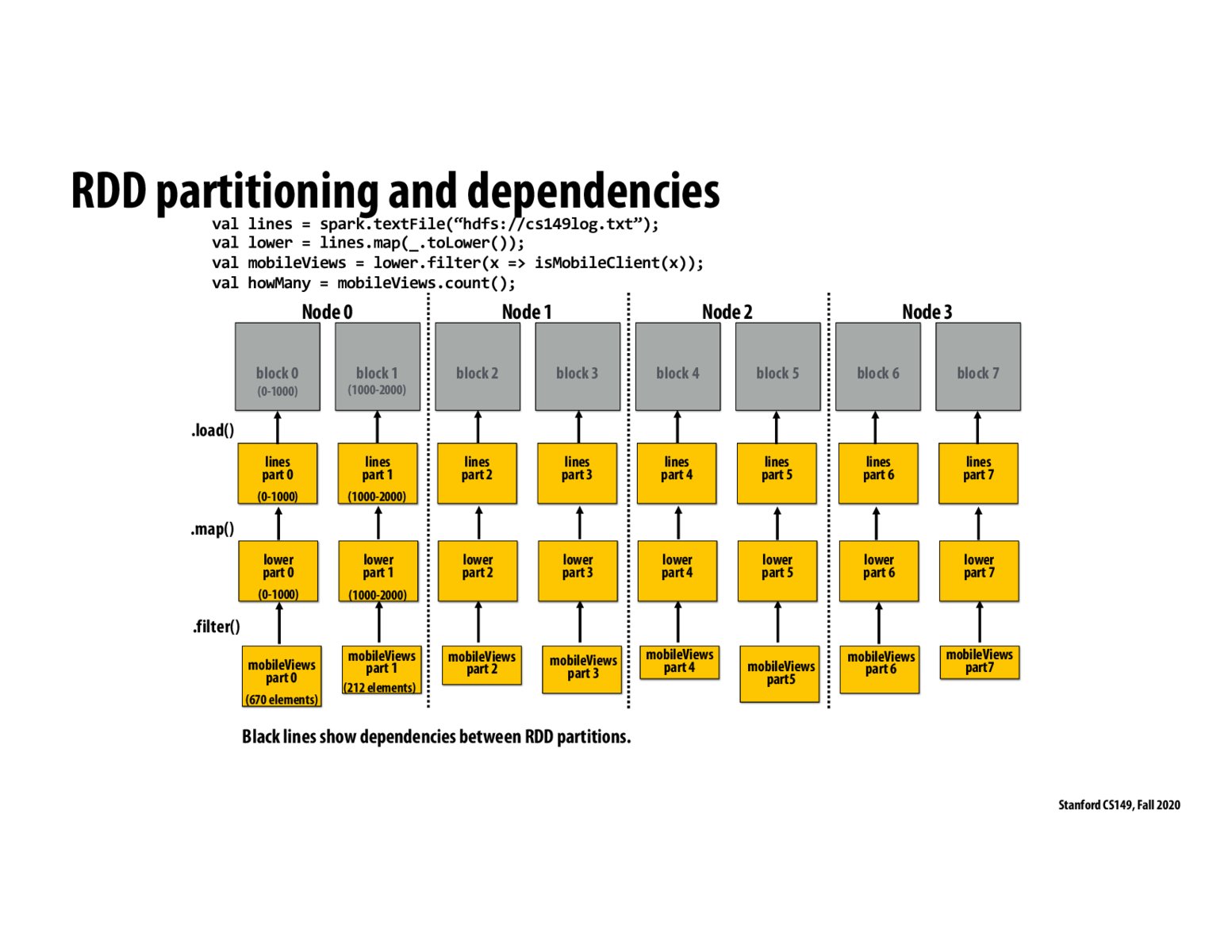
I think we still store all of them, which makes in-memory storage expensive.

dishpanda
Also confused about this. Is this another illustration of the previous slide showing the problem and not the solution?

potato
I was under the assumption that the previous slide showed what would happen IF spark stored everything, while this slide shows the dependencies and was a transition into the future slides, where we learn that spark just stores the lineage.

cmchiang
Is the key that these operations are lazy and we just put a tag on the previous result.
Please log in to leave a comment.
I'm still confused on how the RDDs are stored in this picture. Do we first store "lines part 0" on Node 0, then compute "lower part 0" and discard "lines part 0"? Is that the difference between the previous slide saying "in-memory is too expensive"?