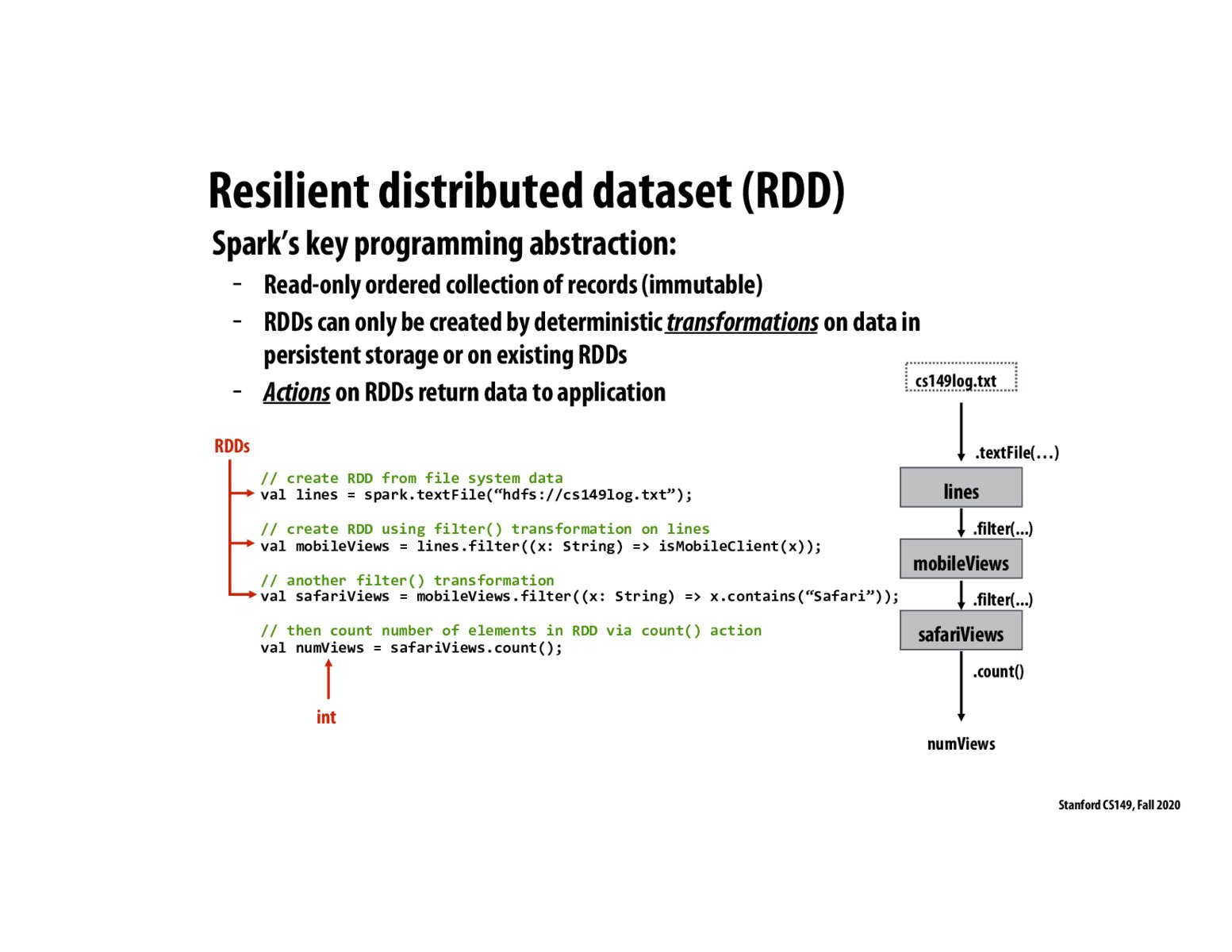


As Kayvon pointed out in lecture, one way to think about RDDs is to draw a parallel to the data-parallel computation model discussed earlier in class. We can think of a RDD as an immutable "sequence", where we perform transformations ("parallel computations", e.g. map, prefixSum) to get other RDDs ("sequences"), and actions ("sequence-to-number computations", e.g. reduce, fold) to get summary statistics.
The main difference, as I understand it, is that SPARK RDDs work well in a distributed, fault-tolerant setting.

Part of the resiliency of this design is the fact that we can keep logs of the operations done on some input. So, if a node doing a computation goes down, we have kept track of the operations we have done and can launch the same computation on another node. This is a reason why the sequence of operations as shown in this slide are helpful.

My understanding of the importance of RDD being immutable is to avoid the overhead of data synchronization with other nodes.

One thing I think is an advantage of Spark is productivity. Since each transformation yields another RDD, the programmer can very easily chain transformations together in a single line.
Please log in to leave a comment.
Where are the RDDs stored? When are they removed?