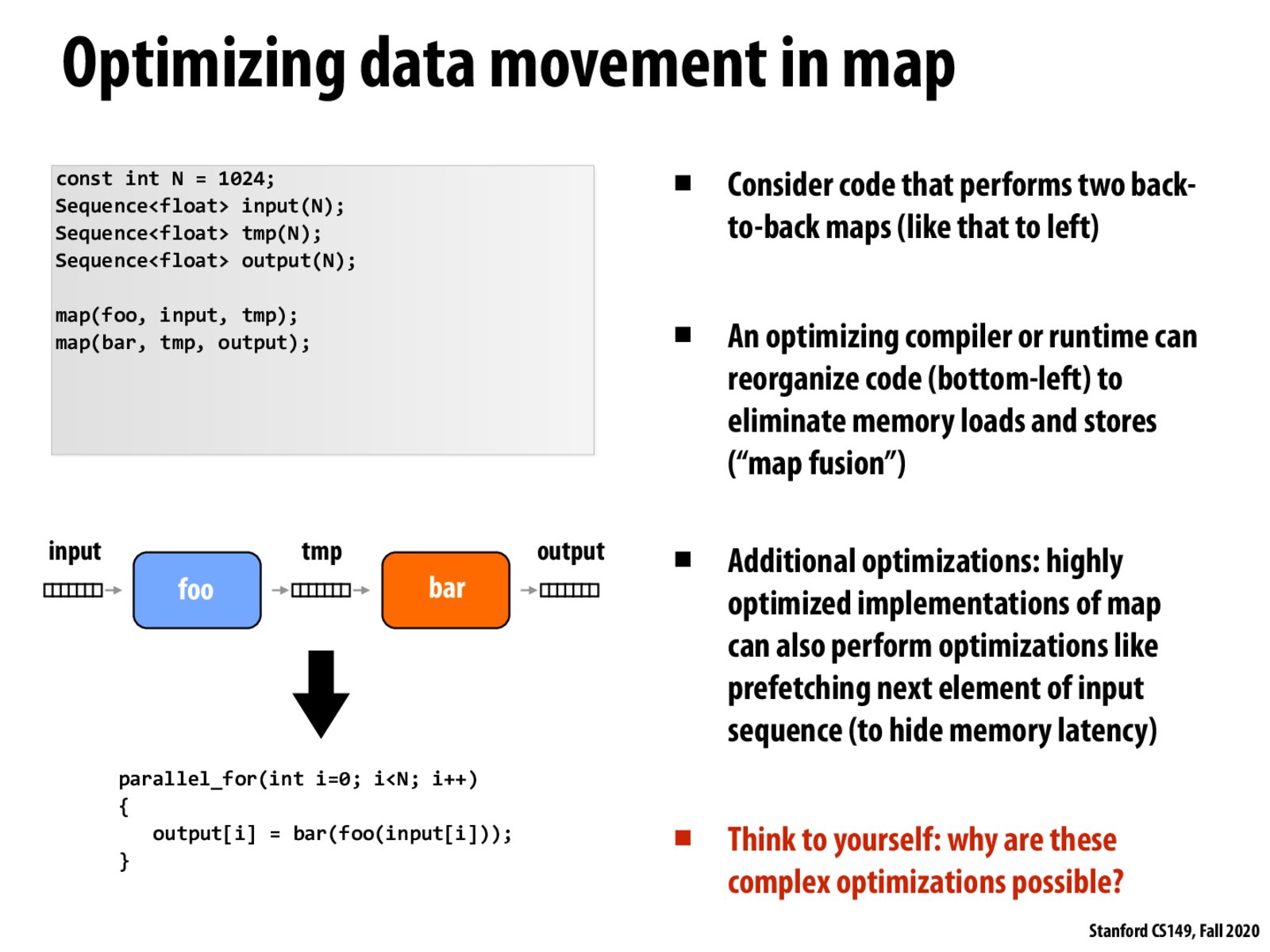


So, here we assume that both bar and foo will process input[i] independent of other elements in input right?

Though not really directly related, but this concept reminds me how SparkSQL can use Catalyst and optimize a chain of map/transform functions. Being able to see the big picture and optimize the intermediate steps is a huge improvement in performance.

@zecheng, I think foo will process input[i] independently of other elements of input, however, unless foo and bar are fused, I don't think foo acts on elements of input.

These complex optimizations are possible because of the rigid assumptions we make when doing a data-parallel operation like map. Since we know each element is independent and we know we operate on one element at a time with no side effects, we can do things like map fusion and prefetching of adjacent elements.

Just to clarify, does the tmp value never leave execution context (e.g. registers) and hence never cost memory transfer bandwidth?

@Ethan I have the same assumption but I am curious what would happen if the size of tmp is too large to be loaded into the cache as a whole.
Please log in to leave a comment.
How do optimizations like map fusion interact with the concept of passing by reference/value? Specifically, suppose that bar is a C++ function which takes an argument of type float& rather than float (or float&&). Is the compiler able to work around this, or would we be unable to perform the above map fusion optimization?