This reminds me of Baidu/Uber/Horovod's ring-allreduce framework for deep learning parallelization over MPI (which I admit I also don't quite understand). How exactly does this ring bus work? Can each ring be thought of as a physical wire? What happens when multiple cores try to send over the ring at once? What makes a ring better better than a central bus where each core is connected to each cache?
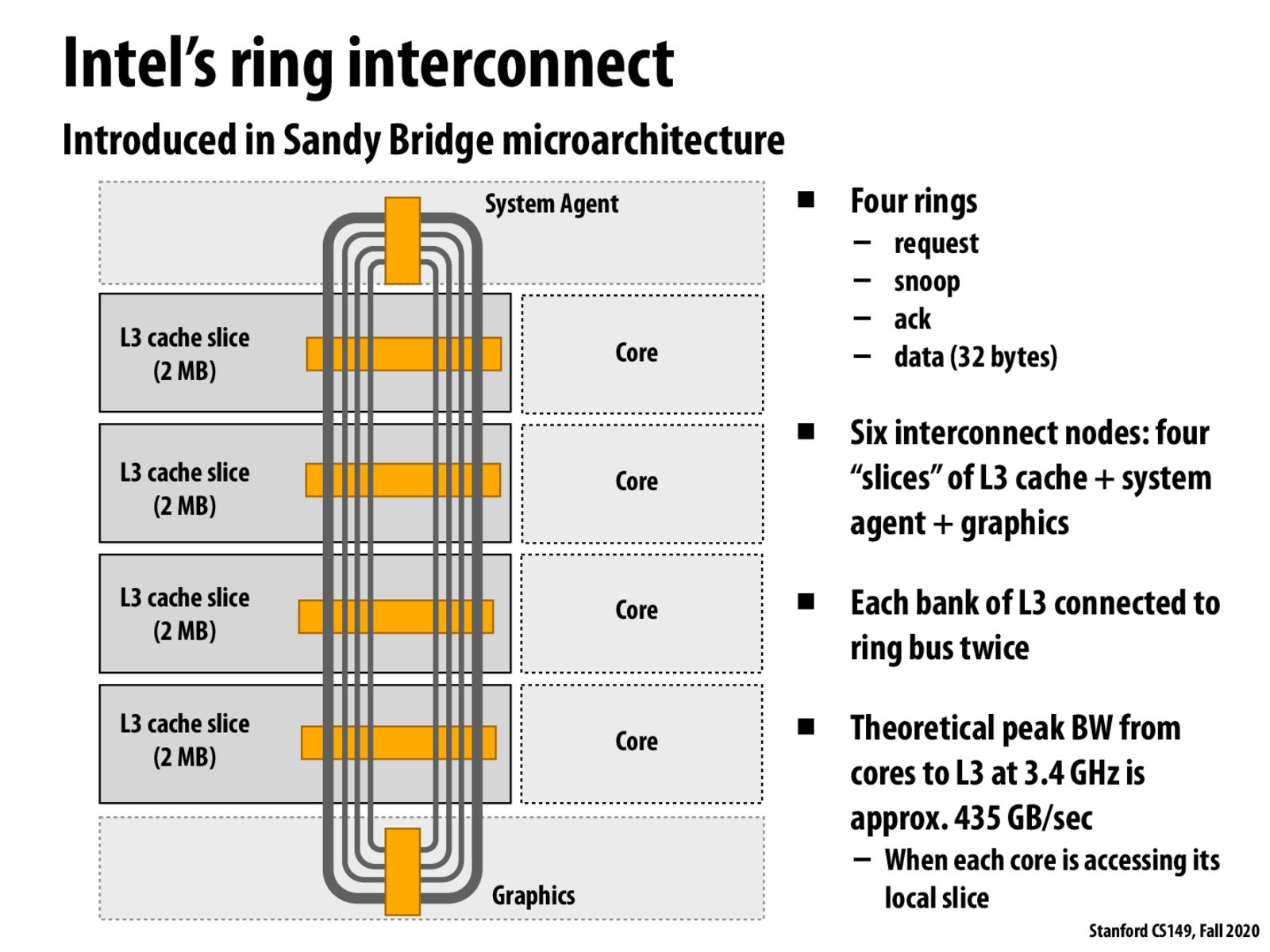

This reminds me of Baidu/Uber/Horovod's ring-allreduce framework for deep learning parallelization over MPI (which I admit I also don't quite understand). How exactly does this ring bus work? Can each ring be thought of as a physical wire? What happens when multiple cores try to send over the ring at once? What makes a ring better better than a central bus where each core is connected to each cache?