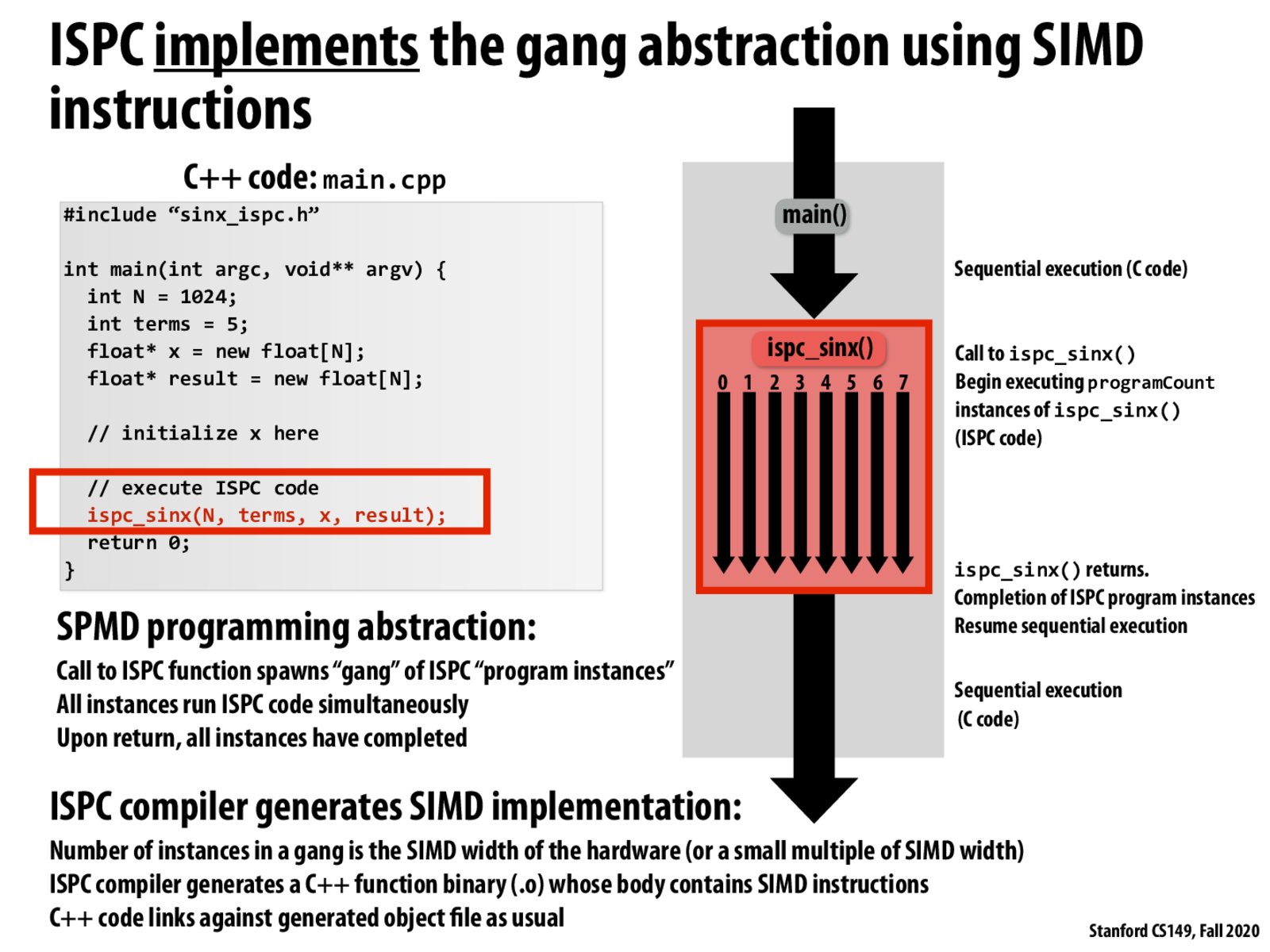


@suninhouse I'm not sure I understand, doesn't this slide say that the number of instances in a gang will always be the SIMD width or greater? How would one increase the number of gangs? I don't think multiple gangs could run simultaneously.

The number of instances in a gang is a compile-time option for ISPC. (Since the compiler needs to know what instructions to emit). As you might imagine, there are options for the common vector widths of x86, such as 4-wide, 8-wide. It's also common to use twice the vector width, for some more sophisticated reasons (hint: loop unrolling for ILP). A good discussion is here:
https://ispc.github.io/ispc.html#selecting-the-compilation-target
https://ispc.github.io/perfguide.html#choosing-a-target-vector-width

Is it possible that simultaenous operations(on one 8-wide vector) finish at different time, so execution will stall for the next set of 8-wide vector instructions, or will the program instance that finished executing first can proceed to executing the next instruction? Does having # program instances > vector width help in this case?

I think in SIMD the gang shares a program counter so all program instances finish at the same time, lanes that are done are masked. The way program instances > vector width might help based on the ispc guide seems to be it amortizes the cost of execution of check of the branch condition in the loop over more program instances and secondly it allows more pipelining if there are enough registers since we can prefetch enough inputs to keep the pipeline filled since these are supposed to be independent? Otherwise the pipeline might need to stall for data hazards.

@thread17 @weimin. To add on, I highly recommend tying this discussion with program 3 p.1 in assignment 1. It is a good segue to understanding how program instances finishing at the same time can impact performance.

@thread17 @weimin @rubensan Keeping the train rolling with another thought. I think having a gang size greater than the SIMD width will capitalize on ILP. In this case, you would want your gang size to be a multiple of the SIMD width to maximize utilization. The ISPC docs say that doubling the compiled gang size will often do the trick.
Please log in to leave a comment.
If the number of instances in a gang is smaller than the SIMD width of the hardware, then it would not be more efficiently since it is not fully utilizing the available SIMD units with the exception that if the total workload is very small, and some cores are idle, then we may want to increase the number of gangs (thus decreasing the number of instances within each gang) so that all cores available are being utilized.