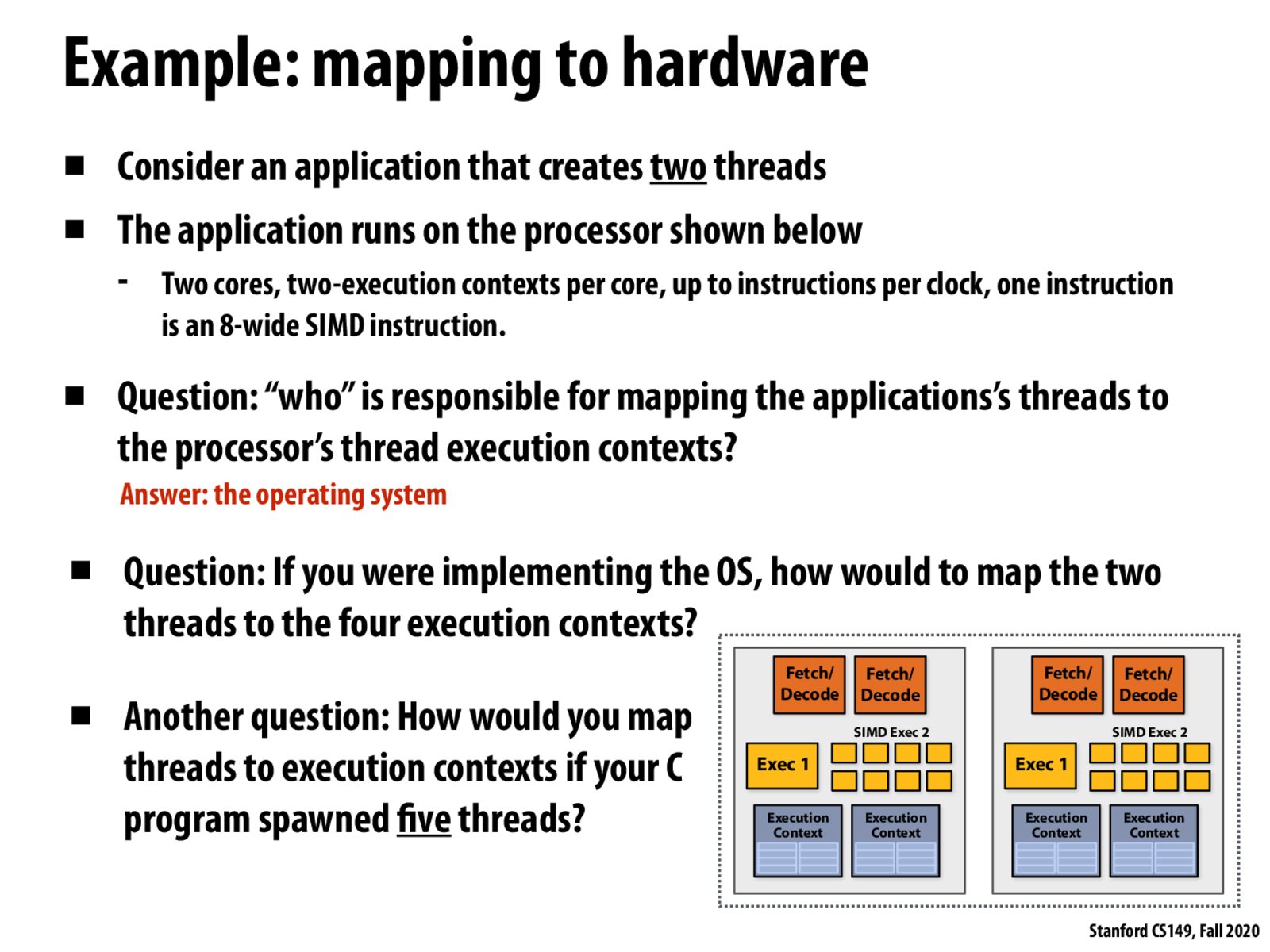


From lecture: OS scheduling decisions depends on the circumstances. In the case of the fourth bullet point, it would make sense to put our two threads on different cores, because there is a fixed amount of execution resources on a core (yellow boxes in these diagrams), and threads on that core must share those execution resources. However, if the two threads were communicating heavily with each other, it might lower costs of communication, etc. to put the threads on the same core, because each core shares an L1 cache. See also slide 22.

This isn't directly related to this slide, but I'm wondering about how threads map to processor architectures that look like the processor block diagrams here. Since we have two fetch/decode units, two Exec "units" (one for serial instructions, one for SIMD), and two exec context units. Does this mean that in some cases we have multiple threads running on the same core concurrently? I imagine this isn't always possible (i.e. not always able to find one serial instruction, one simd instruction to run concurrently), but I was just unsure if that was possible since this seems to basically say that a single core can run two threads or more if we added additional fetch, exec, and context units.

@swkonz I think what you're getting at is 100% possible, and is done in practice. When a core has support for 2 execution contexts, 2 fetch/decode units, 1 serial ALU and 1 set of vectorized ALUs, we basically have a situation where effectively a single core can run two threads at once (simultaneous multithreading), presumably under the assumption that it can find one serial operation and one vector operation from the other of course. That's why on the assignment when we work on the myth machines, we're dealing with machines that only have 4 cores, but each core is 2x hyperthreaded which for all intents and purposes allows us to approach it as if we have capacity to execute 8 threads on the hardware at once (that is, the OS knows it can map up to 8 software threads onto hardware execution contexts at any given point in time, not limited to assigning only 1 per core).

For the last problem we can look at the resource and data dependencies among the 5 threads and map them in a way that minimizes hazards. To minimize the impact we would like to do this at compile time so we need a way to describe these hazards to the compiler.

If we have more threads than execution contexts, we would interleave the thread executions on our execution contexts. This will ensure that we achieve as concurrent execution as possible, especially if the threads had a blocking instruction which stalls, say like a memory access.

How does the operating system decide to interleave processing when we have more threads than execution environments? For example, how does it decide the proportion of resources to give to background threads vs. a program the user might be actively using?

@harrymellsop For your example, a priority scheduling algo might be used where "priority" can be OS-defined. At the end of a time slice, the OS grabs the highest priority thread to place onto the execution units. Many algorithms allow for some computation that can dynamically adjust priorities to limit starvation. Here is a taste of a certain scheduling algo (a publicly available doc from CS140 last year): https://www.scs.stanford.edu/15wi-cs140/pintos/pintos_7.html.

@harrymellsop different scheduling algorithms have different pros/cons. For example, throughput (number of threads that complete per unit of time), turnaround time (avg time for threads to complete), response time (time the request spends waiting in a queue before it starts running). CPUs are generally fast enough to interleave execution of multiple threads each second using a priority scheduling algorithm without it being noticeable to the user

What is the criteria by which the OS/processor might decide to do ILP for one thread versus running both of them together on the processor? Can it automatically decide between multi-threading and superscalar execution?

What if I only have scalar or vector operations? Does it mean that only the serial or vector ALU is used in the entire process?
Yeah, I think if you had an instruction stream composed of only vector instructions, then only the vector ALU would be utilized. However, I think that's a relatively uncommon occurrence when considered across many instruction streams that a process is responsible for executing, so its generally able to get better utilization by pulling vector operations from one thread and scalar operations from another thread.
Please log in to leave a comment.
To schedule threads when there are more threads than execution contexts, one reasonable principle appears to be that we should keep all execution context occupied while also ensuring some fair share of time slices by different threads, which would involve swapping in and out threads.