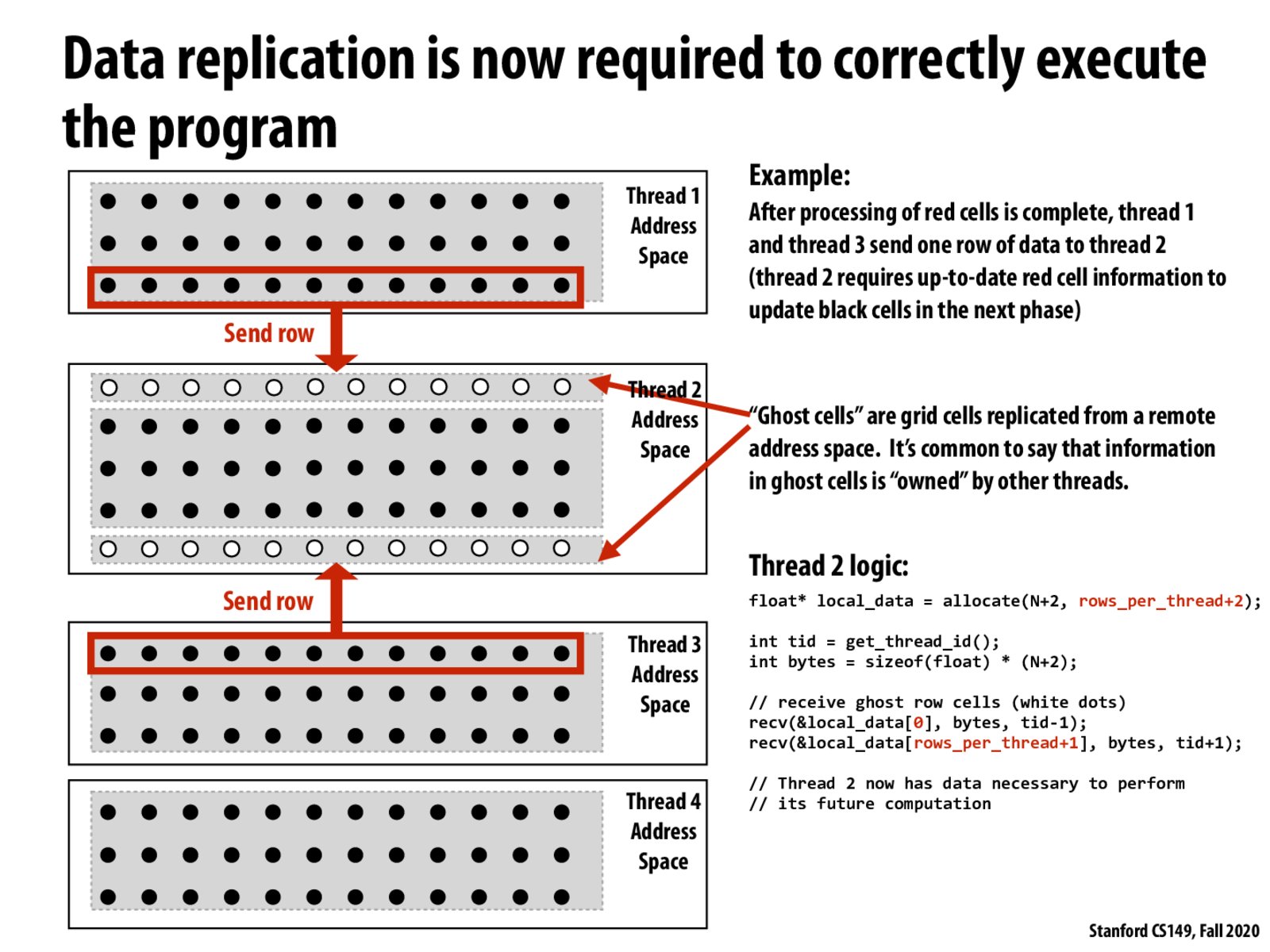


@pmp, I don't think that solution works, because regardless of how many rows you have in a specific thread, the two rows at the top and bottom of that block of rows will always require information from outside of the thread, which would then require message passing. In this context, if thread 2 actually just worked with five threads instead of three, the two white rows would still require information from threads 1 and 3, respectively.
Thanks Felix! I think I'm describing something different - having five rows sent to each thread, but each thread only computing 3 rows worth of the function.
It's essentially the same as the eventual implementation just without message-passing.

@pmp I think Felix was talking about dependencies. Those white rows passed to Thread 2 are not original numbers from the input, but numbers already replaced by calculation results from Thread 1 & 3.

@pnp Sorry I'm so late to the game but I think I see what you're saying. The essential difference between what you're suggesting and what the slide currently has is that your message passing scheme is centralized whereas the slide's is peer-to-peer.
Every iteration of the solver, some centralized node (i.e. the main thread) would be in charge of giving each thread the elements in its domain of responsibility + the two rows on its boundary (these would have to be copied). In the slide's implementation, these rows are not bestowed by a central entity but neighboring threads.

I think if we did the central node idea as stated it would be less scalable because if we had a much larger grid then we would need to send an ever increasing number of rows. Also from a hardware point of view if this dispatch thread is on one core it has to wait for all the cores running the job.
Please log in to leave a comment.
Is message passing the best way to fix this problem in this scenario? (I understand this is an illustrative example, but I'm curious.)
Couldn't you just initially give each thread 5 rows of data and ask them to compute 3 rows of answers? As in, shouldn't you give threads overlapping blocks of the arrays?