Back to Lecture Thumbnails

wzz

tspint
I also thought the answer to the question in lecture about how libraries implement these to perform well on multiple different platforms was to have giant switch statements that run different sections of the code depending on the architecture. Automatically doing this is still an open problem.

harrymellsop
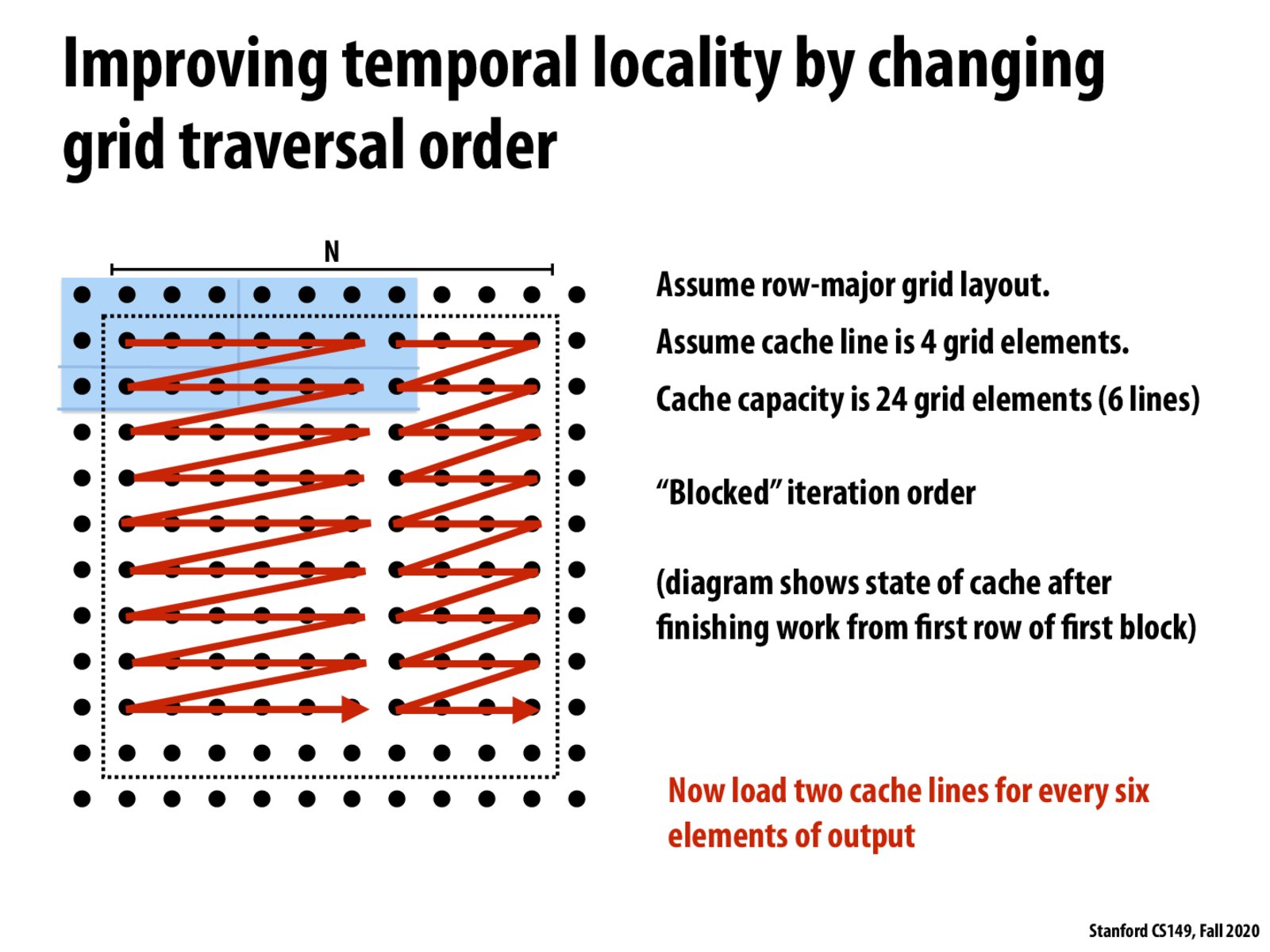
In practice, how would we actually do this (when the machine that runs our code may have a variable cache line size). Presumably, the compiler can't really do this, as it requires knowledge about the specific problem space. Nor is it really practical oftentimes for us to write a bunch of if condition checks to run the most efficient version. Is there some intrinsic we might be able to use to help us?
Please log in to leave a comment.
This approach takes advantage of the fact that we know exactly the input data layout and cache line / size, so we can optimize our cache hit rate. In practice, from what I understand in lecture, what compilers do is generate multiple compiled copies of functions, each with a traversal order (e.g. go 6 nodes v. 14 nodes per row before going on the next row) optimized for certain common cache sizes / architectures, then at runtime picking the best one.
@kayvon would love to clarify how this optimization is done in practice.