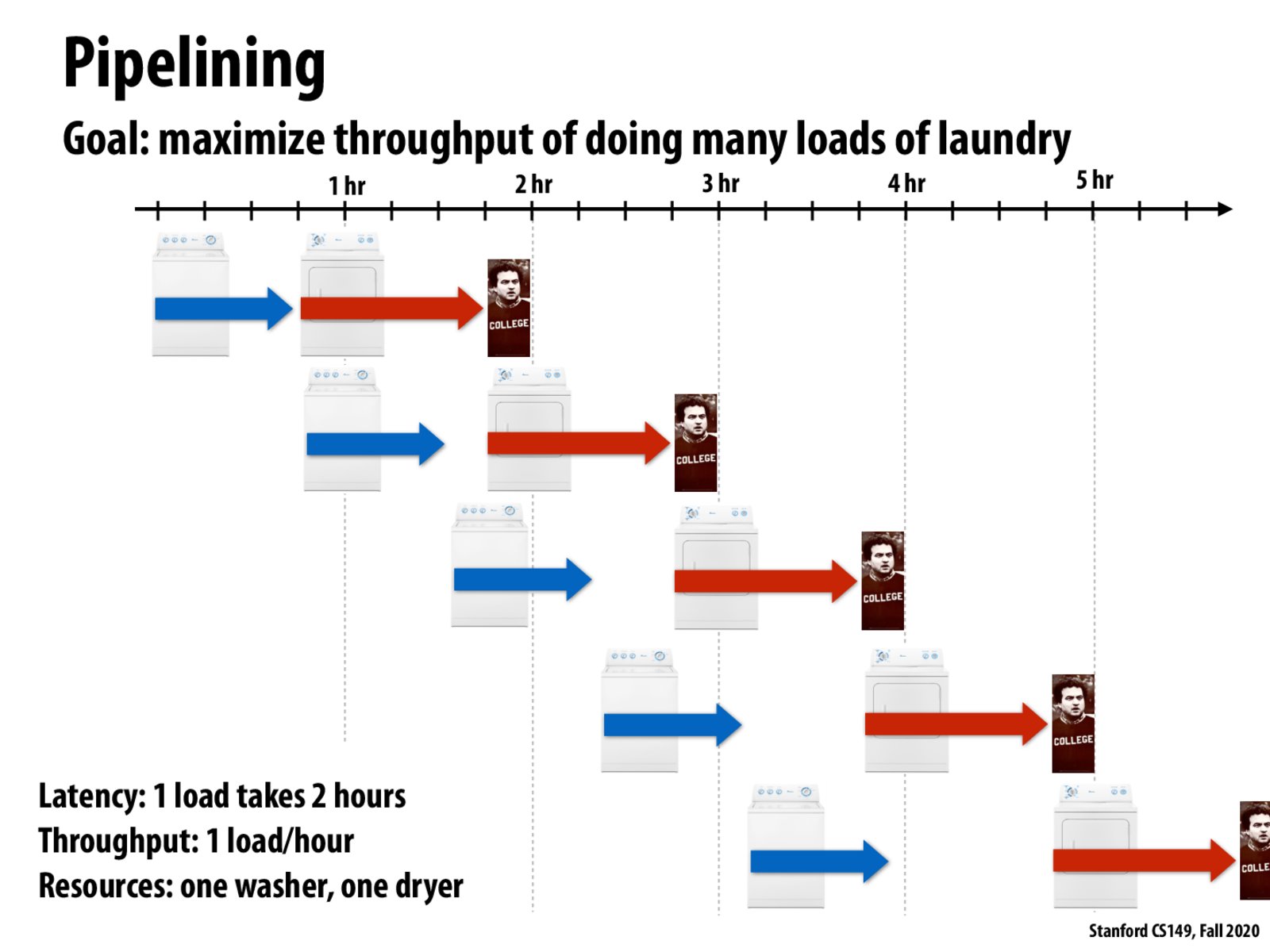


A helpful way to determine throughput is to simply ask yourself "How often is work completed?". Here, every hour, a load of laundry is completed, so throughput is 1 load/hour.

1 load/hour is based on the observation that starting from the 2nd hour, every hour there is a load finished. But would it also be reasonable to compute throughput including the first hour? For example, in the first 5 hours, there are 4 loads finished, so the throughput would instead be 0.8 load/hour? I don't think this is correct because I think throughput calculation probably would let the number of hours approach infinity?
It also appears that the distance between washer and dryer would become larger until it converges to a certain constant.
So what would be the most rigorous way of calculating throughput in this case? Or am I missing something simple?

I think this relates to the notion of "effective throughput" on slide 26. It would be correct to say that to complete the first 4 loads the effective throughput is 0.8 load / hr. To say throughput without the qualifier "effective" means letting the period approach infinity.

Here it takes 6 hours to finish 5 loads, but apart from the first round, each additional load takes 1 extra hour, so the throughput is 1 load per hour. Imagine that we have infinite loads, the final throughput will converge to this value.
To follow up on my own comments: in calculating throughput, we are typically taking the number of clocks approaching infinity. Or more simply put, we should ignore the constant overhead at the start.
Please log in to leave a comment.
As noted in the lecture, throughput basically depends on the slower pace, which is the dryer in this example. While throughput increases, the latency remains unchanged in this case.