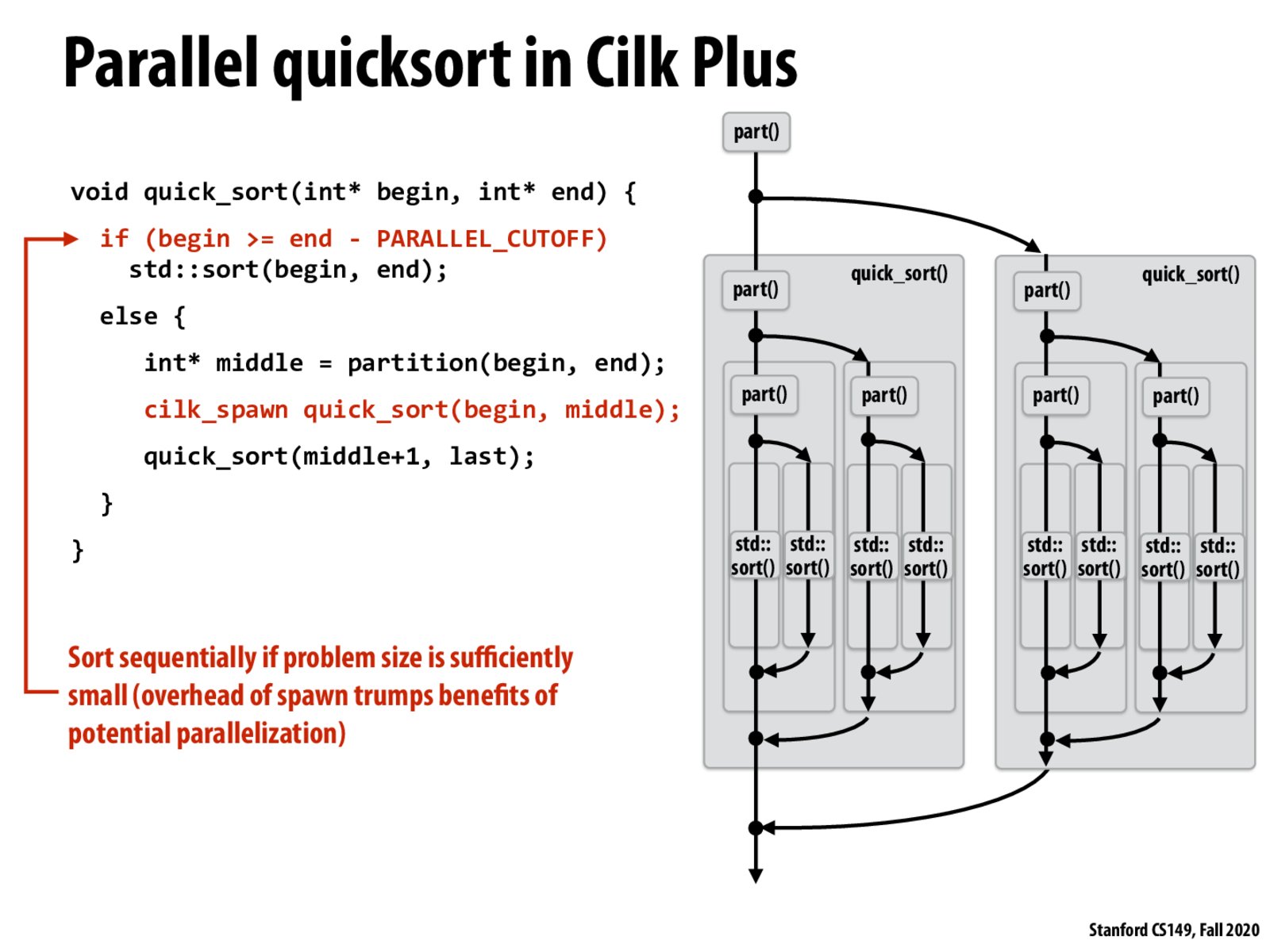


Yup! Also, a recursive split (as opposed to a for-loop split) has some nice benefits too, even if the algorithm doesn't strictly depend upon recursion. By splitting recursively, we allow larger chunks of the work to be "stolen" by other threads, which can in turn be divided and stolen by subsequent threads. The net effect is better load balancing, since the workload can be dynamically split up over time. In contrast, a simple for-loop implementation would statically split up the work ahead of time. See Slide 47!

@gpu, thanks for pointing out the connection between slide 28 and slide 47! To provide some details regarding how thread 0 mentioned in slide 47 takes larger chunk of workload, basically since cilk_spawn is an async thread (it doesn't wait!), the quick_sort function in thread 0 will keep recurse and call itself, ending up with calling quick_sort on a bunch of "(middle+1, last)", where the "(begin, middle)" section will be automatically scheduled for different threads (e.g. thread 1, 2, ..., etc.). Thus we need the "steal" mechanism described on slide 47 to do some load-balancing in order to speed this whole process up.
Please log in to leave a comment.
From my understanding, parallelization can be done using the concept of recursion. Specifically, until the if statement about the size of each group is satisfied, total work is splited using the quick_sort function. This eventually sort sequentially if problem size is small enough to be independent to each other.