

In addition to Fork-Join, Cilk++ has a parallel loop called cilk_for that compiles to a divide and conquer strategy. It can be combined with SIMD to nest a SIMD loop inside of the parallel loop, allowing chunks of data to be processed as vectors in parallel.
(https://scc.ustc.edu.cn/zlsc/tc4600/intel/2017.0.098/compiler_c/common/core/GUID-ABF330B0-FEDA-43CD-9393-48CD6A43063C.html)

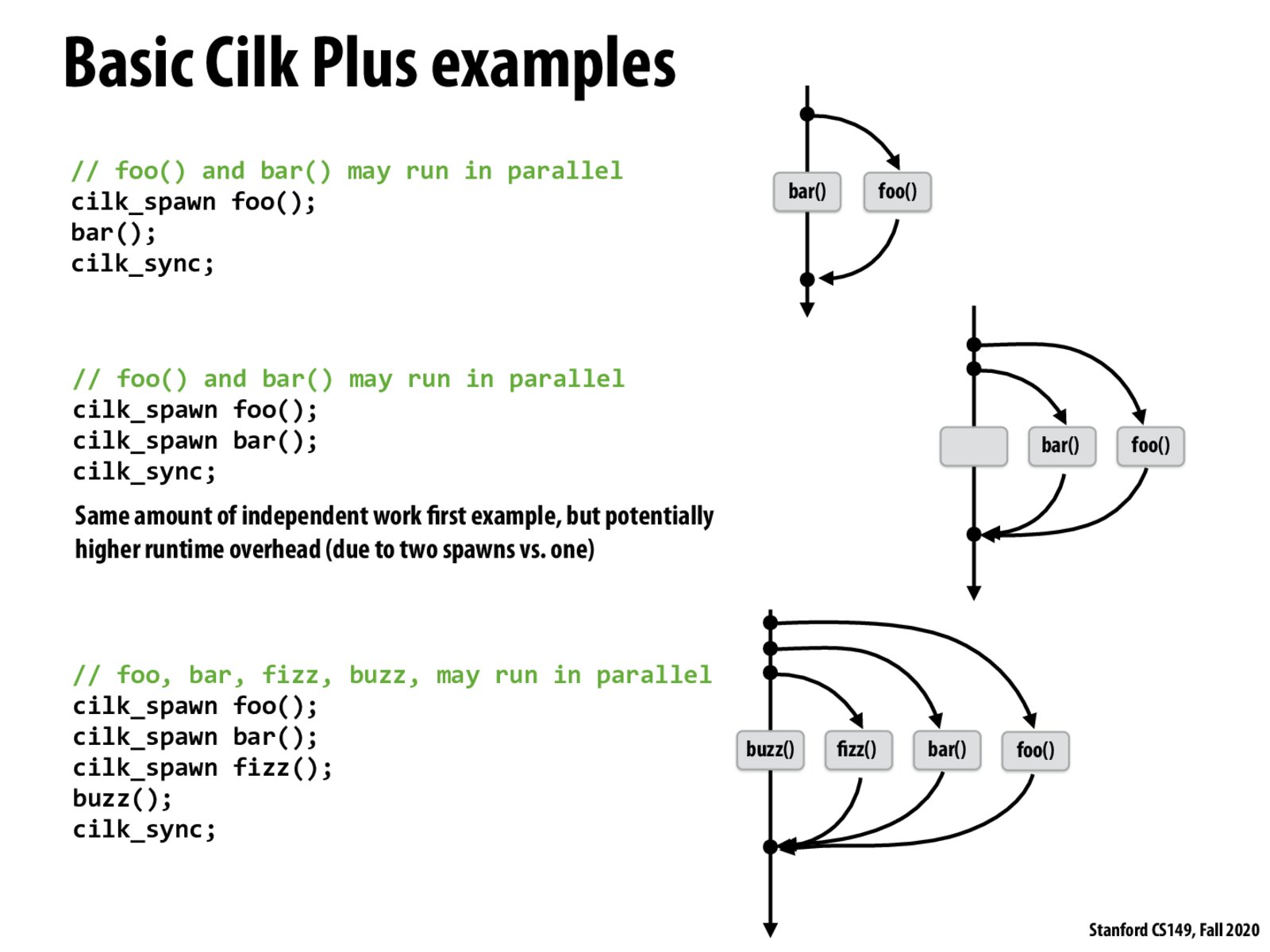
I didn't quite get this part during the lecture, like how is cilk_spawn different from pthread_create and how cilk_sync different from pthread_join?
For example, pthread_join is also telling the system to wait for other threads to finish right? Or does cilk provides more functionality to avoid conflict between threads?

@wanze I think slides here is discussing cilk_spawn and cilk_sync as an abstraction, and pthreads can be one valid implementation.
And slide 30 tells a main difference: not every cilk_spawn creates a new thread - that would waste a lot. Cilk implementation uses a thread pool.

Yes, as @icebear101 mentioned, one implementation uses a pool of threads, equal to the number of execution contexts on the machine. Idle threads then steal work from the queues of busy threads.
Please log in to leave a comment.
Is there a fundamental reason why the child and continuation are given different statuses, instead of just being the two paths of execution after a split? After all, the overall diagram looks like a DAG. Is it just that this is the natural way we write programs, and this convention makes the implementation of divide-and-conquer patterns efficient?