

@ruilin I think randomly permutating the tasks could be a bad idea as it yields unacceptable performance in worst cases, especially when granularity of tasks is not fine enough. In fact, as a well researched problem, there are some strategies in task scheduling, dealing with different needs, and sometimes with mathematical guarantees on bounds. https://en.wikipedia.org/wiki/Scheduling_(computing)

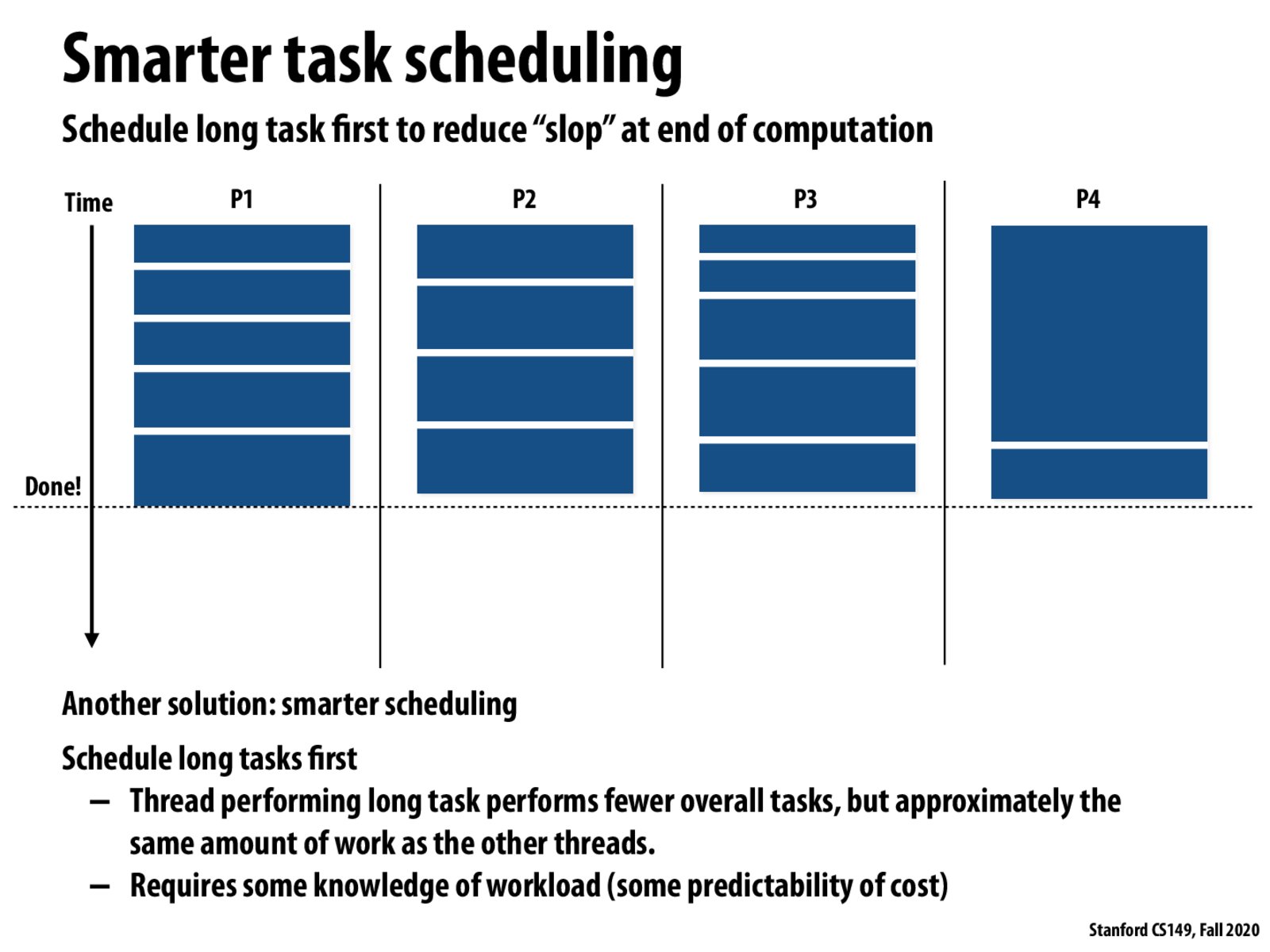
@ruilin In this particular example, I believe there will be no load imbalance only if the long task is scheduled as one of the first 4. If each processor completes two short tasks before the long task is assigned, then there will be an imbalance.
For me, the intuition for putting longer tasks first is similar to bin packing: you want to put the large items in first to make sure they fit, before filling the space with smaller items.
Agree with @jt and @potato. I think it depends on if we care about the worse case performance or average case performance. In this example, if there are a lot of tasks, the probability that the long task is the last few is O(1/num_tasks).

So another suggested optimisation for the primes example would be to start with i = N and decrement the counter because you expect larger numbers to take longer to compute on average.

Can we use a priority queue for task assignment in this case? I think if we are given the cost of each task then it might be practical to do so. The remaining problem here is how to have a good estimation of the cost...

@assignment I think you're definitely right that if we were able to make accurate predictions of task length, then organizing tasks in a priority queue would definitely be the way to go with "higher priority" corresponding to longer tasks, which would be claimed by worker threads first. As you point out though, the tricky part is having enough domain knowledge about the work tasks being run in order to make an accurate prediction. If you consider something like Mandelbrot, there doesn't seem to be any a priori knowledge that we could have that would help us predict whether or not a pixel is going to take few iterations (end up black) or many iterations (end up white) so that seems like a particularly difficult challenge to solve.

I think another important distinction is that same workload is expectation does not mean no load imbalance in expectation. The load imbalance more has to do the variance in the workload, which is nonzero in random permutation, even though the expectation of the actual amount of work is the same.
Please log in to leave a comment.
Can you randomly permute the task and then do a static assignment. Then, at least in expectation, there is no load imbalance.