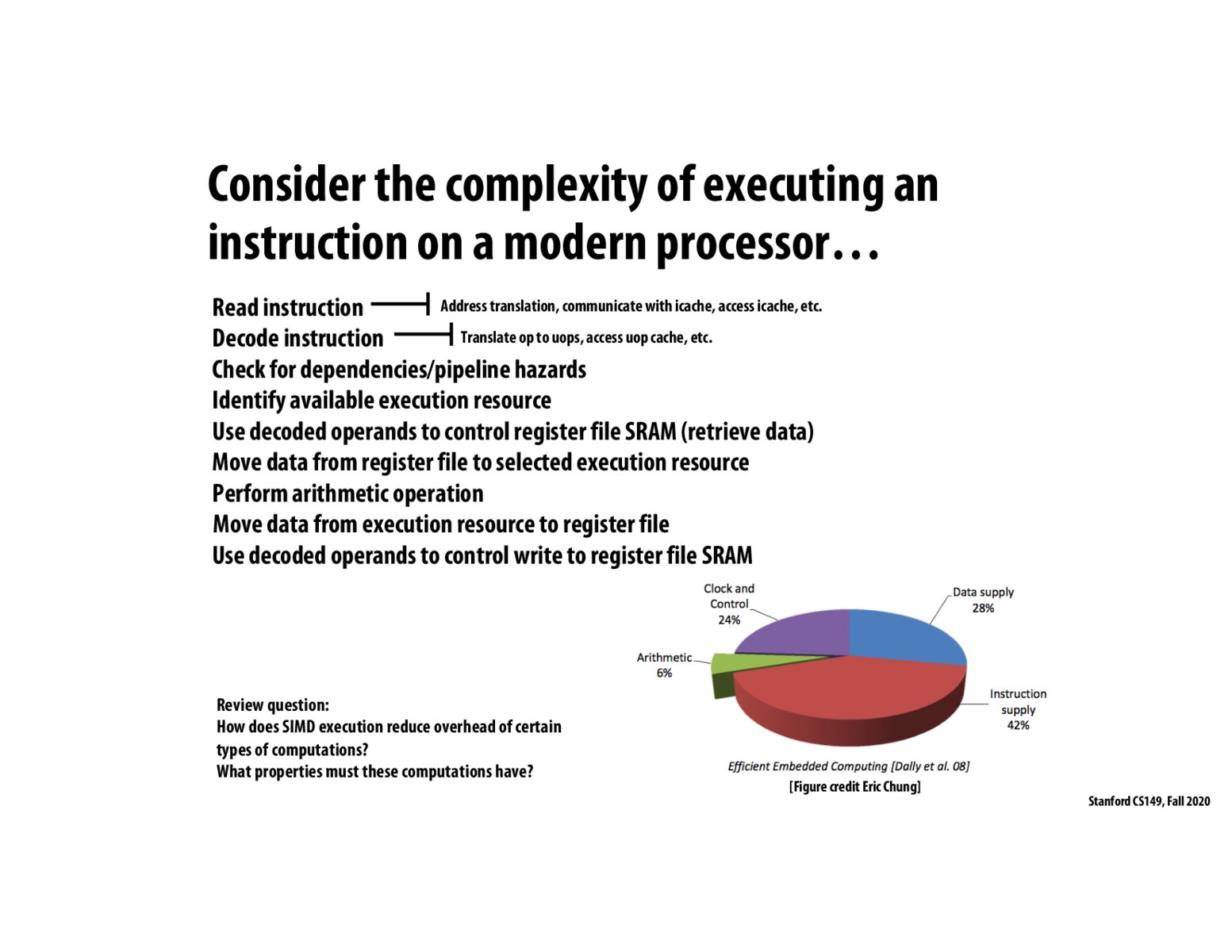


The vast majority of power consumption in executing a given instruction comes as overhead (clocking, data/instruction supply), with a much smaller percentage being the operation explicitly denoted by the instruction. SIMD execution improves this proportion by only requiring 1 pass of overhead for N instructions (if those N instructions can be done in a SIMD vector op), as opposed to requiring N overhead if those instructions were sequential.

To add to what's already been said, explicitly for SIMD we are going to be able to reduce the relative contributions of instruction supply and clock/control areas of the pie chart. The impact on data supply and arithmetic is less clear, and going to depend on many other factors about where data is coming from in the system.

This chart is indicating that the actual arithmetic of executing an instruction is a very low portion of the total energy used by a processor for that instruction, while the overhead of running the processor and supplying instructions and data are a much larger fraction. This explains why SIMD execution can reduce overheads, as SIMD execution does more arithmetic for each instruction fetched and decoded. I am not sure about the answer to the second question, but I imagine it might have something to do with SIMD divergence, as highly divergent SIMD workloads will reduce the amount of arithmetic done per instruction. This slide also helps explain why ASICs have a lower ability to improve the efficiency of floating-point operations, compared to other workloads, as floating-point operations are more computationally intense, meaning that overhead is a less important factor.

@bayfc Regarding the second question "what properties must these computations have", I think you are right about divergence. I think the question may also be getting at something mentioned in previous slides - our computations must be parallelizable [which I guess includes non-divergence], and our program needs to be compute bound. A memory bound program does not benefit from SIMD units.
Please log in to leave a comment.
SIMD execution reduces instruction supply in the pie chart because the ALUs will run on the same instruction. These computations must run the same instruction on a vector/array type of data structure.