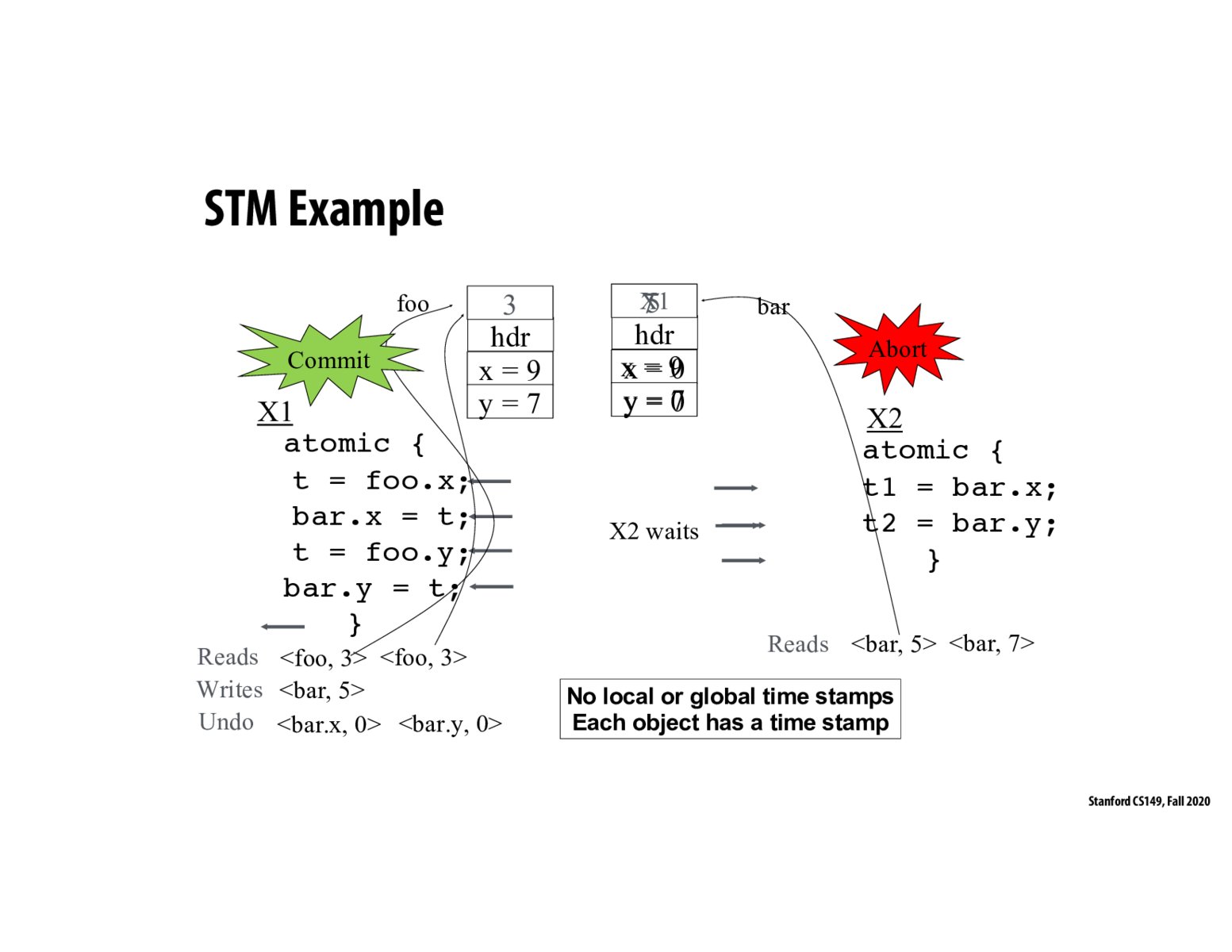


I am still confused here. What does it mean by no timestamps? And why does X2 abort? Stamp 7 > 5?

@ufxela I think you can conclude that this particular STM system uses object-level conflict detection. Other STM systems might not.
@Nian I'm confused too, so hopefully an instructor or someone who knows could help break down what happened in this slide, but to answer your specific questions:
- A few slides back we talked about there being a global time stamp for the entire TM system and each transaction having its own local time stamp that references the global time stamp. In this example, this is not the case. Instead, each object has its own time stamp. They're 2 different ways of tracking when something was last updated.
- Transaction 2 aborts because when it was trying to commit, it saw that it performed a read at time stamp 5 and another at time stamp 7, so the data has changed some time in the middle of the transaction. Thus, it needs to abort.

I am not sure whether I missed something: I wonder whether we can track the abortions.

@orz I don't think we can keep track of the aborted transactions. I'm not sure we need to, unless this type of record is used to detect live locks?

Why is the timestamp 0 for the undo log? Is that a timestamp, or something else?

@haiyuem I feel like that is not timestamp; it is the original value of x and y.
@icebear101 I see. Thanks!

I think one of the key points is that X1 keeps a lock on bar at time step 5, so X2 doesn't get to read the rest of bar once X1 writes the first field. If X2 read the whole value of bar before X1 wrote any values, the data would be consistent with serial order with x = 0, y = 0

Isn't X1 and X2 are atomic? Why can X2 execute while X1 is in execution?
@wanze They appear atomic, but their real schedules interleave.

I ended up coming back to this slide a lot with confusion during WA6 (particularly because I had to figure out what were version numbers, what were stored values, etc). But I’ll try to summarize my understanding now for those that might also be confused:
When you track read, you want to keep track of the object you read and its version number at the time—helpful for when committing and you need to validate. E.g
When you track write, you also want to keep track of the object you are writing to, the version at which it was at when you first wrote to it, and then you want to keep track of the lock around it—this is helpful knowing that the version number might change when you go to commit. And note, the lock is just around the object.
When you track undo, that’s the only place where you really need to keep track of the an actual value and where it belongs. In reading and writing, you don’t need to keep track of the actual values because in the eager versioning scheme you optimistically read and pessimistically write.
Please log in to leave a comment.
From this slide, can we conclude that STM uses object level conflict detection granularity?