Back to Lecture Thumbnails

pmp

haiyuem
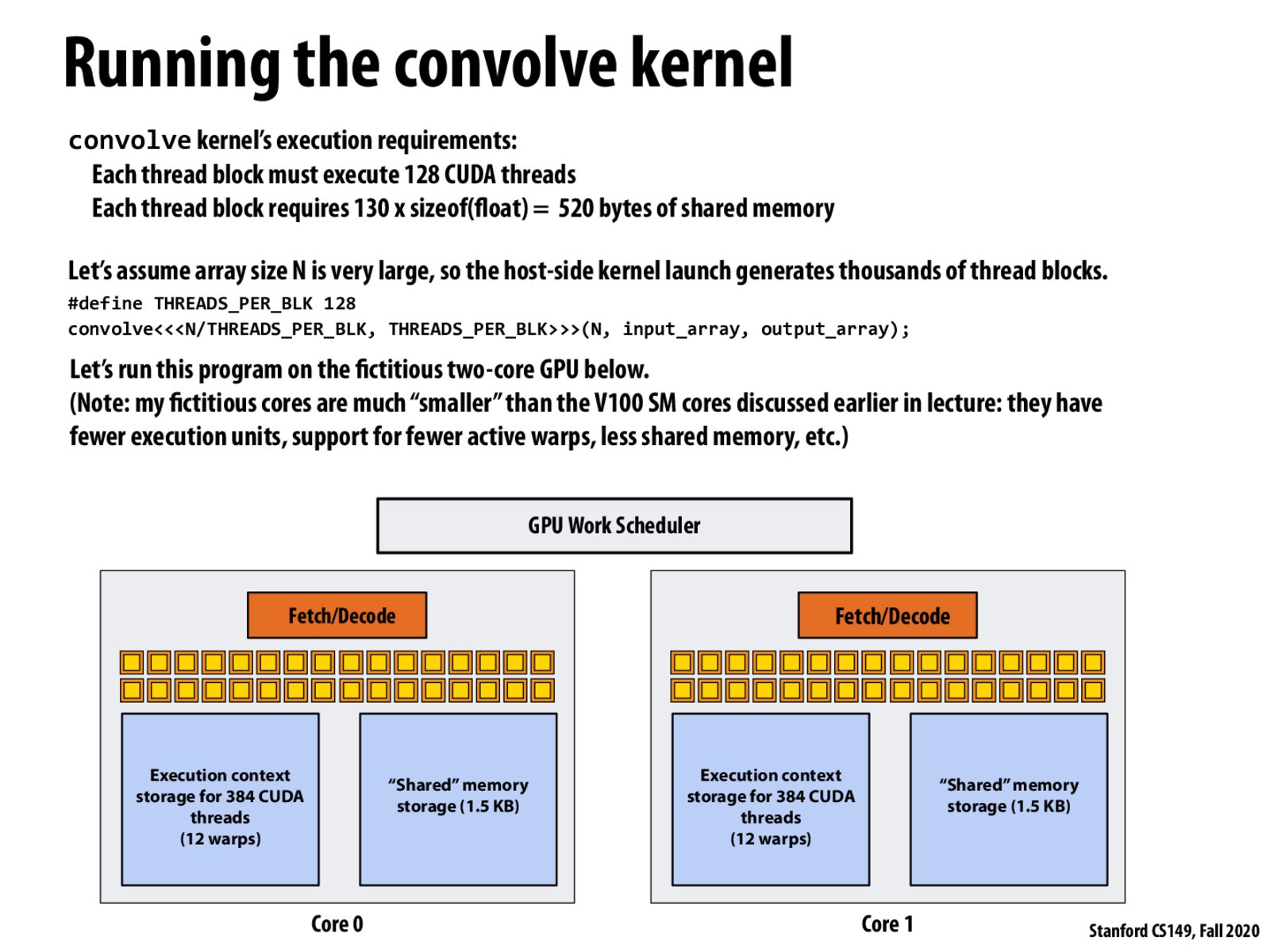
@pmp I think the granularity is at the thread block level. The work scheduler will schedule the incoming block into the first available core.
pmp
That was my assumption. Where thread block is like an ISPC task, by which I mean the granularity at which you let the hardware/OS take over.

nanoxh
Q: why we are reading in 130 floats, when we have 128 threads? Also, can someone point me to the slide where the discussion of 128 vs. 3*130 happened?
haiyuem
@nanoxh This is a convolution and each thread needs the value before and after its own index. So the threads at the head and tail need the 2 extra floats.
nanoxh
@haiyuem Thank you! I understand it now.
Please log in to leave a comment.
How does the GPU work scheduler work?
Does it look at the shape of the input data to figure out how to assign work?