

what's a case where we as programmers wouldn't want as many threads as there are datapoints (specifically to the case where we would want more threads than datapoints)?

In order to make the best of hardware resources, programmers should take the responsibility of designing the number of blocks and number of threads per block, so that all blocks could be running at the same time.

I'm still confused about what a CUDA thread is w.r.t. our previous abstractions.
It looks like: each warp must execute the same instructions so it behaves like the ISPC gang abstraction, just bigger. However, in implementation it's different because, when compiled, ISPC uses one execution context to run an N-wide instruction, where N is the width of vector ops allowed on your ALU.
But since you must execute the same instruction on each thread in a warp, doesn't that mean that "CUDA warp ~ execution context/CPU thread as we thought of them before"?

@pmp
I am also confused about CUDA threads. It seems to me that a CUDA thread is a logical thread (like pthread in CPU) but multiple threads are executed in a warp using SIMD instructions, which is different from CPU implementation where SIMD instructions are executed within one thread.

@ufxela I think in most cases there are far more data points than available threads if we're running DL applications. @pmp @user1234 I think CUDA threads are actual hardware execution units (e.g. adders) residing in GPU. Threads physically exist separately in hardware, but they share the same instruction, so I think they're more like ISPC with one execution context and multiple ALUs.

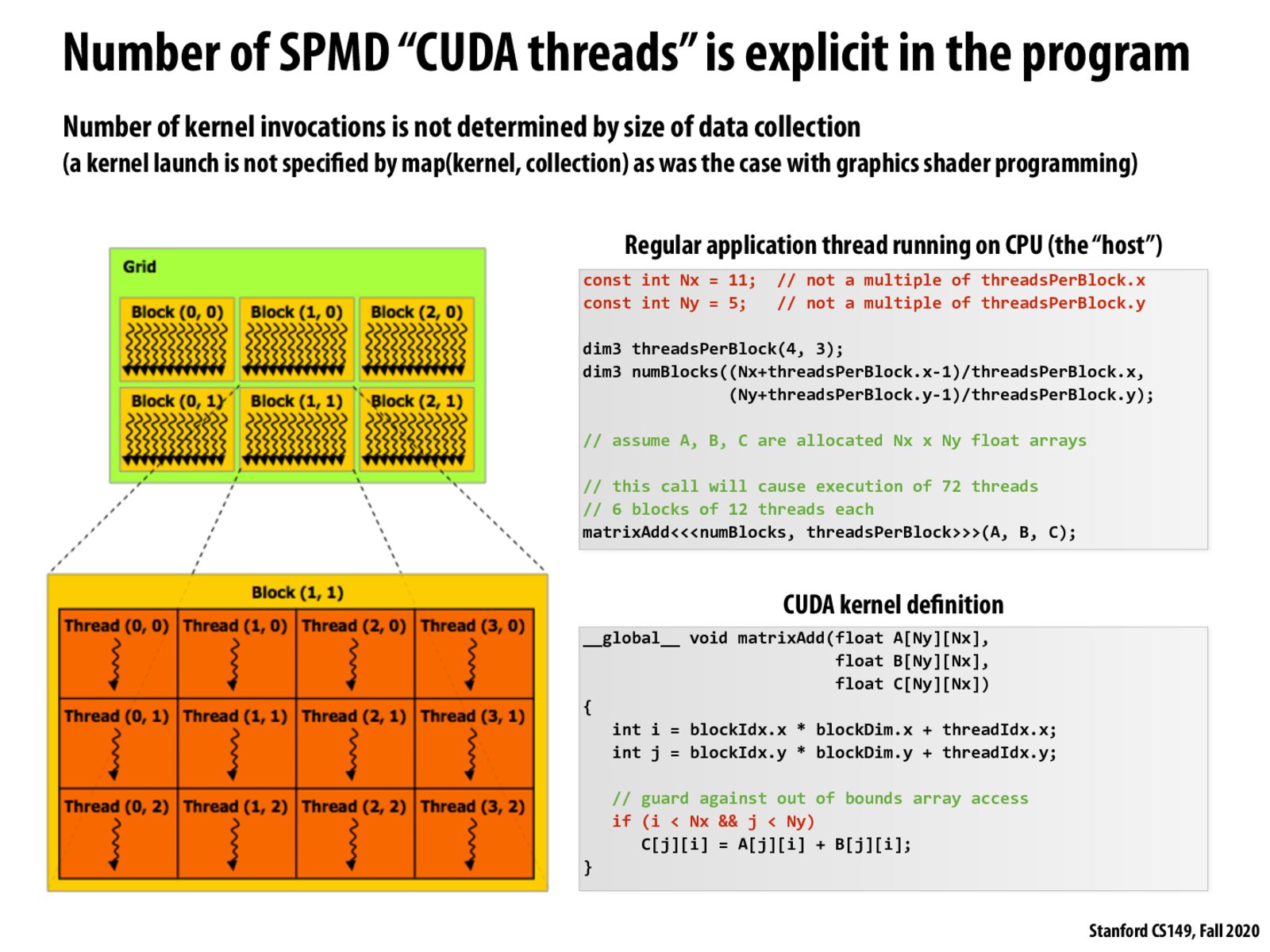
It might be dumb, but I'm kinda confused by the code for computing number of blocks here: (Nx+threadsPerBlock.x-1)/threadsPerBlock.x Isn't it (11+4-1)/4 = 3.5 instead of 4?

From what I understand, you can think of there being many threads in a warp that executes one instruction across all threads. Each core can have multiple warps. So if you had a warp of 32 threads, you could run an instruction and it would be executed across all threads simultaneously. (I would appreciate feedback on this comment if it is incorrect!)
Please log in to leave a comment.
In other words, you the programmer (not the size of the array you're operating on) specify the number of CUDA threads and blocks that are created. This means that if you end up spawning more threads than you have data values, some of the threads must not do any work.