When computing matrix multiplication, in one clock cycle, x0 can get sent into the first PE w00 and then send it to the PE w10 to continue the multiplication of the dot product. All these processing elements are extremely close together, which helps computational efficiency since data can be sent to the right and down to multiple processing units. Ultimately, the result for y ends up in the bottom row.
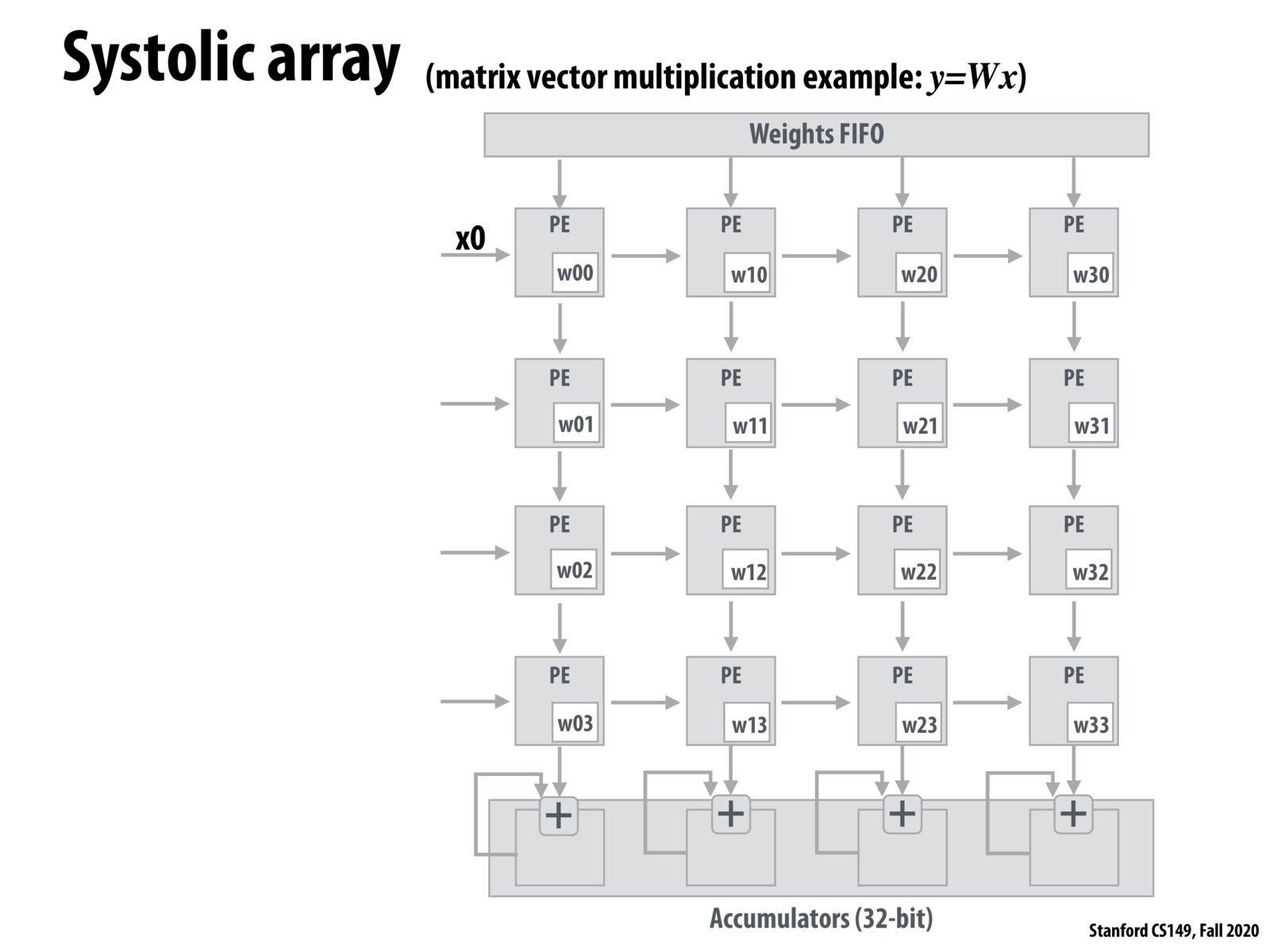

When computing matrix multiplication, in one clock cycle, x0 can get sent into the first PE w00 and then send it to the PE w10 to continue the multiplication of the dot product. All these processing elements are extremely close together, which helps computational efficiency since data can be sent to the right and down to multiple processing units. Ultimately, the result for y ends up in the bottom row.