

I think it's interesting that when we take classes like 224N and 231N, we don't really discuss the energy tradeoff and the total compute time required to train the network itself. I hope in the future those classes also evolve to give more time to topics like this.

I heard a talk from the author of the KataGo Go-playing AI, and he talked about how the main challenge in competing with Google and the like is the training time, as he has but a small fraction of the compute hardware that they have. In his effort to compete, he discovered a number of ways to make the training easier, which suggests that in general, we might be leaving a lot of training efficiency on the table when we (Google et al) can just throw a bunch of compute at the problem.

^Completely agree with sagoyal! Most of the deep learning classes just assume access to tons of compute. I think it's great that in CS149 we got to see this problem from another perspective, and see how much work went into supporting things like GPUs!

^^ I also found this conversation about energy tradeoff in various deep learning classes interesting, and came across this paper if anyone’s interested!
https://www.sciencedirect.com/science/article/pii/S0743731518308773
It essentially overviews how energy consumption is measured/estimated in machine learning applications. I though the coolest thing is that this paper is quite accessible and readable after taking CS149!
Please log in to leave a comment.
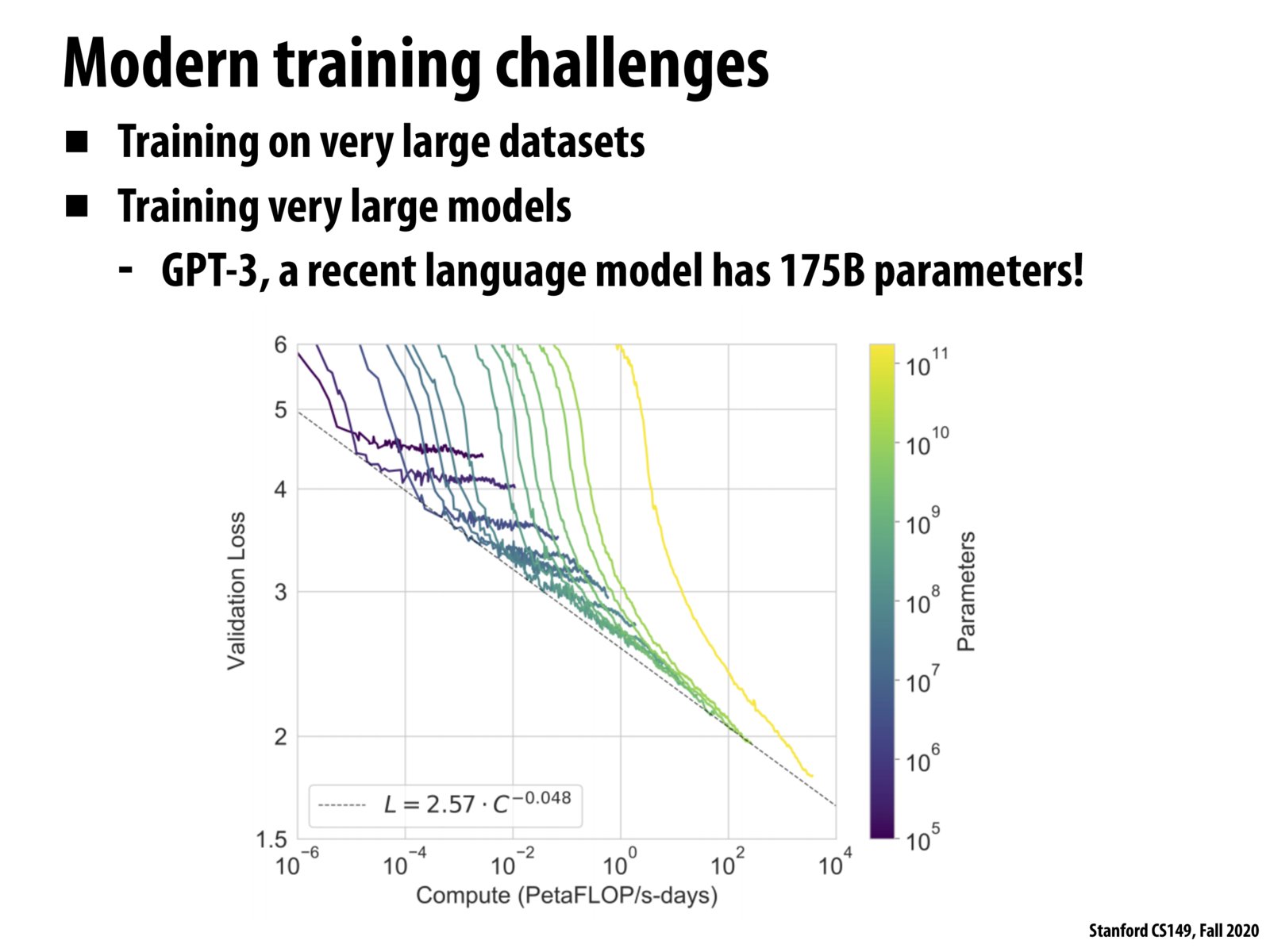
This is relevant to the while loop on the slide before because of how many parameters are required in the call to evaluate_loss_gradient and because the datasets are extremely large (an issue because we want each element to appear in multiple mini batches).
As an aside, GPT-3 is really exciting! This summer, creative programmers used GPT-3 to write some convincing creative fiction (https://www.gwern.net/GPT-3) and fake blogposts (https://www.theverge.com/2020/8/16/21371049/gpt3-hacker-news-ai-blog) among other things.