

The one of the keys to optimizing hardware efficiency is to think about data transfer while minimizing energy expenditures through something like efficient accessing of DRAM.

A recurring theme that we have been seeing through the final stretch of this course is that energy usage is a large component/factor to consider while designing hardware accelerators. This makes the process of designing efficient architectures even more complex because we have to take into account not only perf but how the methods we are getting improved perf may impact energy expenditure.

TPU is a good example of high efficiency of ASIC compared to general purpose CPU/GPU. Custom designed chip can eliminates all the overhead of control. It also shows the inflexibility of ASIC that it cannot easily adapt to changes in machine learning algorithms like sparsity.

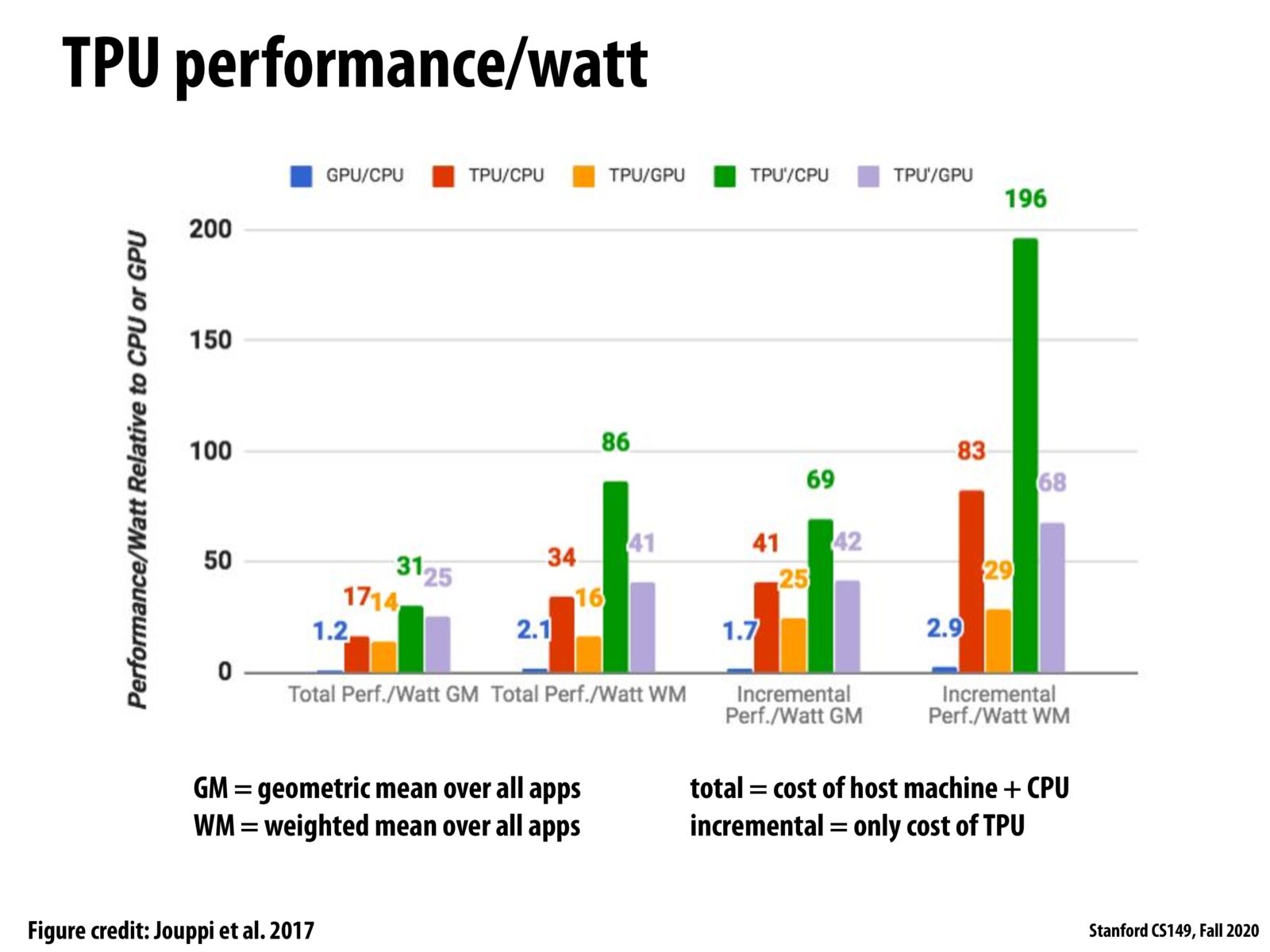
There was a question in class regarding what "TPU prime" in this figure represents – I went to find the original paper and this is what they had to say:
Figure 9. Relative performance/Watt (TDP) of GPU server (blue) and TPU server (red) to CPU server, and TPU server to GPU server (orange). TPU’ is an improved TPU that uses GDDR5 memory (see Section 7). The green bar shows its ratio to the CPU server, and the lavender bar shows its relation to the GPU server. Total includes host server power, but incremental doesn’t. GM and WM are the geometric and weighted means.
Thus, it seems like the TPU prime here is the same base TPU design with improved memory bandwidth from using better memory. Their conclusion from the mentioned Section 7 is that this has the biggest impact on overall performance, quoting the following line: "First, increasing memory bandwidth (memory) has the biggest impact: performance improves 3X on average when memory increases 4X." Another example of the importance of memory bandwidth!

I'm curious, what's the process for running code on a TPU? How do you compile for it? Is this process relatively accessible or do you need to learn yet another toolchain? We learned how we can program GPUs with CUDA, but I'm curious if I can spend a couple hours and end up running something on a TPU.
Please log in to leave a comment.
Thinking spatially is important in thinking about machine learning accelerator hardwares, e.g., how data can be moved across smoothly with minimal energy costs.