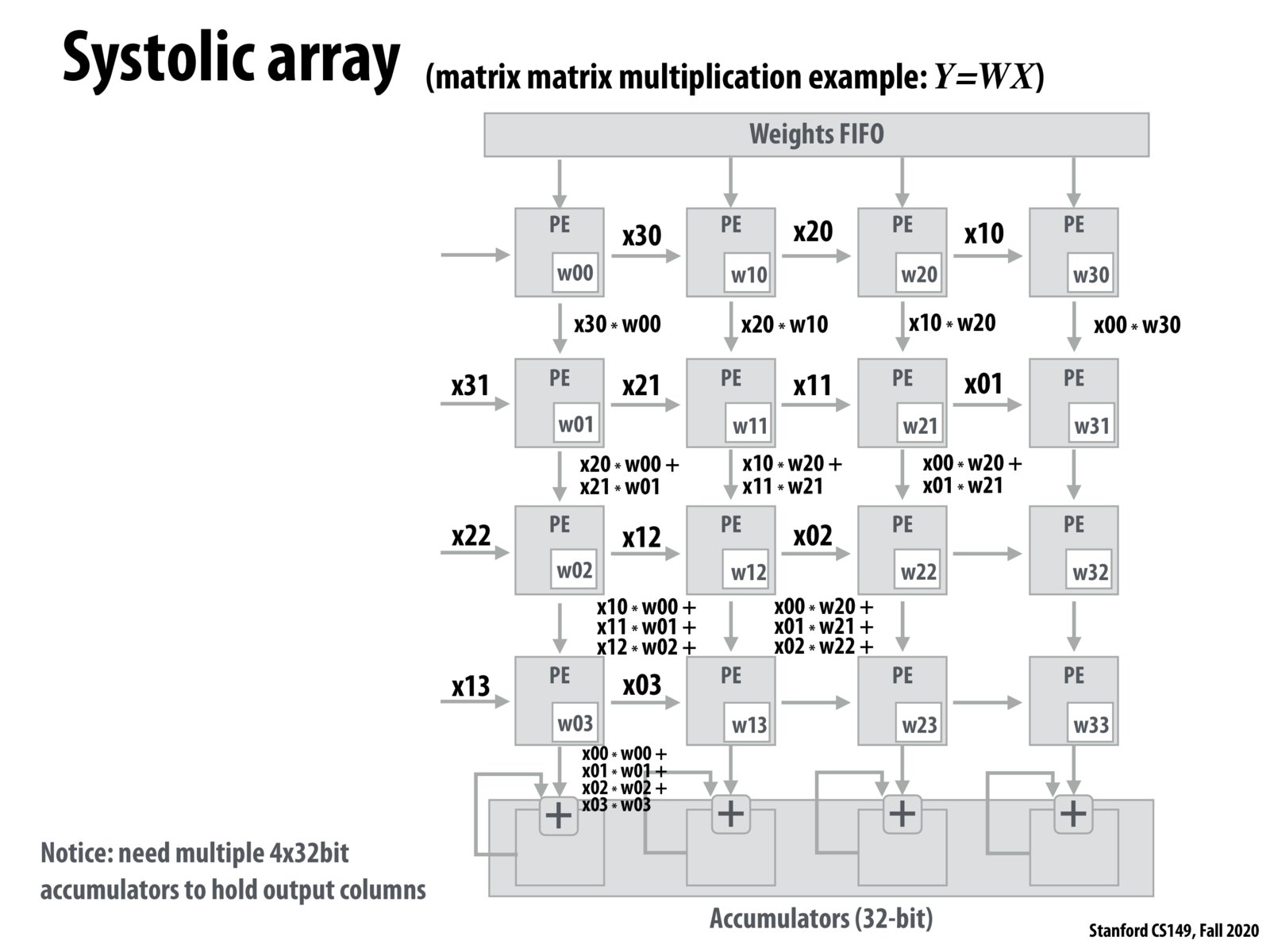


Each processing element essentially takes in an element of the column vector, a weight and an accumulation value and performs this computation: output accumulation = (column_vector_element x weight) + input accumulation.

To optimize matrix multiplication, because even accessing register files can have significant latency, processing elements can be arranged in a grid where data is passed on each iteration to two directly adjacent grid elements. Data is passed down to continue the process of dot producting a column with a row, and passed right so that this can be done for the next row. This direct transfer of data is extremely fast. Although with a vector this leaves most processing elements unused most of the time, by doing matrix multiplication one column at a time, almost all of the processing elements potential is used, although some are still wasted at the beginning and end of the multiplication.

Is it possible to extend this idea out to higher-dimensional tensor multiplication, or other tensor operations that need to be performant? Or are those use-cases rare enough that we maintain this systolic array as the 'building block' and compose tensor operations from this instead?

To perform matrix-vector multiplication, data flows across diagonals of the processor elements. This is inefficient, as at best only 4 (in this example) processing elements are used at any one time.
Utilization can be maximized in the case of matrix-matrix multiplication, where each diagonal is essentially performing a different matrix-vector multiplication. This allows for 100% utilization of the processing elements.
On a different note, the systolic array is highly specialized for matrix operations, and would be not sensible to use for more general-purpose computing. This is a great example of how hardware can be specialized to certain tasks for greater efficiency, at the loss of generality.
Please log in to leave a comment.
In order to do a matrix-matrix multiplication, which is the extension of the matrix-vector multiplication, the data keeps flows from the left continuously (called Systolic array). The first column of Matrix x flows and the second column flows right after the first column and so on (Think about the pipelining). Google has 256x256 multipliers in it, So if the matrix size is smaller than 256x256, you can do very efficient matrix multiplication.