Back to Lecture Thumbnails

suninhouse

bayfc
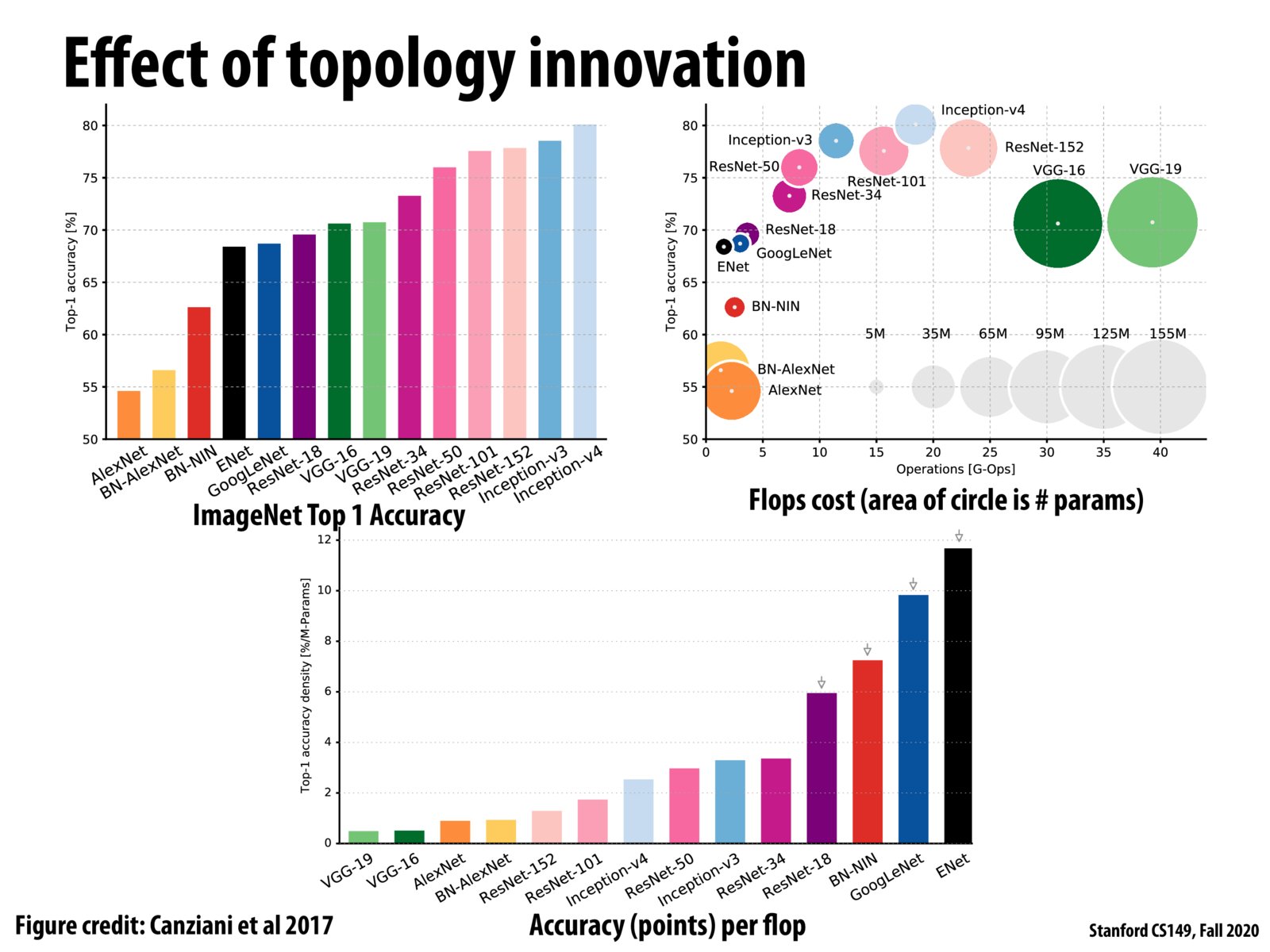
These graphs show that more modern DNNs are able to achieve both greater accuracy and vastly higher performance compared to older DNNs like VGG-16. This indicates in this instance that optimizing the algorithms within the domain was a more effective approach than general optimizations like sparsification which only hid some of the costs of using an inefficient network to begin with.
Please log in to leave a comment.
One trick is to use 1x1 convolution layer to reduce the dimensionality, which is a critical ingredient in Google's Inception: https://towardsdatascience.com/the-clever-trick-behind-googles-inception-the-1-1-convolution-58815b20113