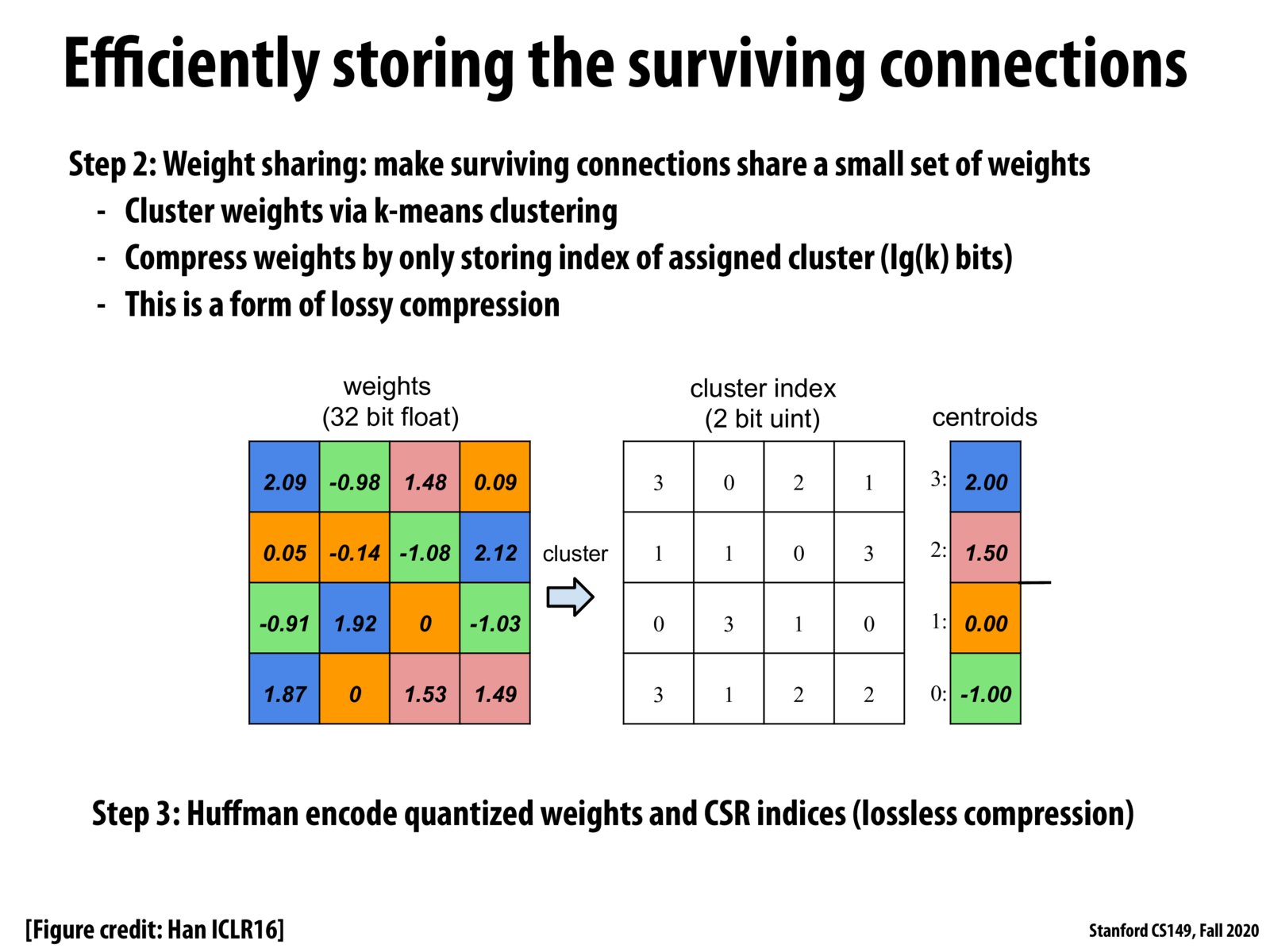


How is the clusters selected from k-means clustering, which may generally produce multiple possible clusters?
In past experience when working with k-means clustering, we typically manually examined to check if the resulting clusters make sense; in this case, I assume that the whole process is automated?

I thought that DNN is sensitive to small perturbations, so if we're sparsifying the weights in this way, wouldn't we hurt the performance (e.g. precision which we didn't talk about a lot) as a result? Or more specifically, are we doing it in training phase or inference phase? If we train a model in normal way, but sparsify it in inference phase, wouldn't it be a problem?

@suninhouse I think K-means clustering will produce multiple possible local optimal clusters, but we don't need the global optimal clusters. I think a local optimal will sometimes be good enough. We can also use better initialization to fix the problem (for example K-means++)
@jt I guess we are training a model in the normal way and sparsify it in inference, it's a trade-off between precision/recall and compression.
@assignment7 yep K-means++ is indeed famous..

@jt the network is already pruned during the training process and it does raise the doubt that it hurts the precision of the network. In step 1, links with zero value can be safely removed since they don't contribute to the output. Other steps introduce deviations but they are arguably corrected in many iterations of training process. In my opinion, different options in network compression should be offered so the machine learning community can choose better and have better ideas on how much precision is sacrificed.

There was also some discussion about pruning out values not exactly at 0 but near it, which I think ties in with the discussion here about the precision of the network- if you remove those before normalization, they could be far more impactful than you'd originally anticipate.
Please log in to leave a comment.
In practice, there are two types of sparsity pattern, the structured sparsity and the unstructured sparsity. The former one requires the weights to follow a particular pattern, say 2:4 structured sparsity supported by NVIDIA's Ampere architecture requires 2 out of 4 continuous elements in the weight matrix are zero. The latter one does not have such requirements.