

Following on here, being able to switch from dense to sparse linear algebra algorithms in some cases could reap enormous benefits. Sparse linalg algorithms are often asymptotically strictly better than their dense counterparts, and it's getting easier and easier to make these choices thanks to technologies like taco.

Are we here primarily optimizing for space or speed?
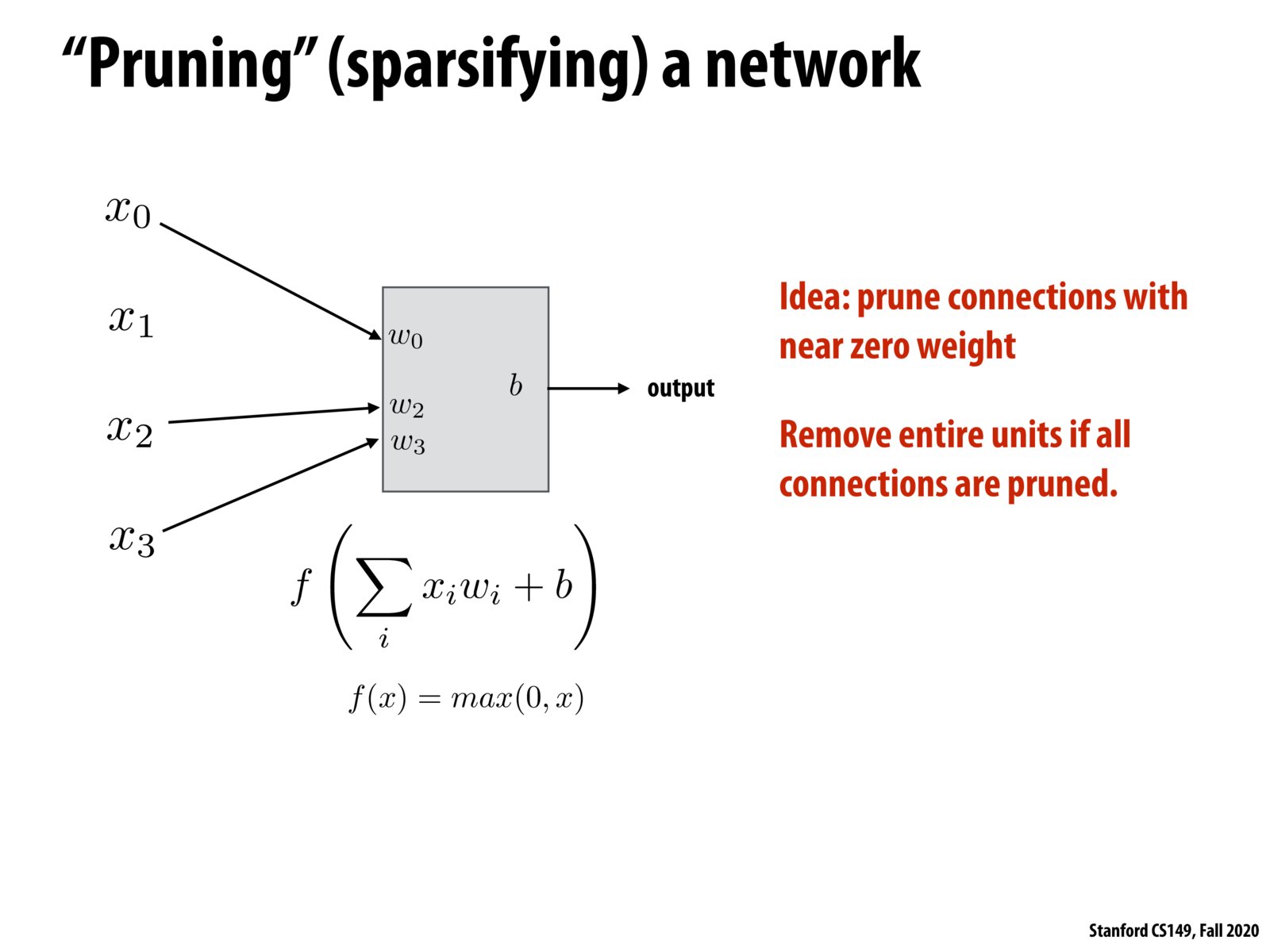
My understanding is that the major benefit is to reduce the number of arithmetic operations (omitting those that are near zero), but we still need memory space for this value in case it is non-zero for other input data.

@wanze I think this provides a benefit still because we can omit near zero values for the rest of the entire computation, since it would clear out any other value that uses the near zero value as a weight.

Is that the pruning can be mainly used for the network using ReLU activations due to the "dying" ReLU issue?
Please log in to leave a comment.
An interesting recent paper shows that 90% of activations in dense neural networks are not significant to the final prediction results. https://arxiv.org/abs/1803.03635.
This has interesting implications for the amount of compute spent on training neural networks if we are computing 10x more activation's than needed during training and inference.