Back to Lecture Thumbnails

suninhouse

jle
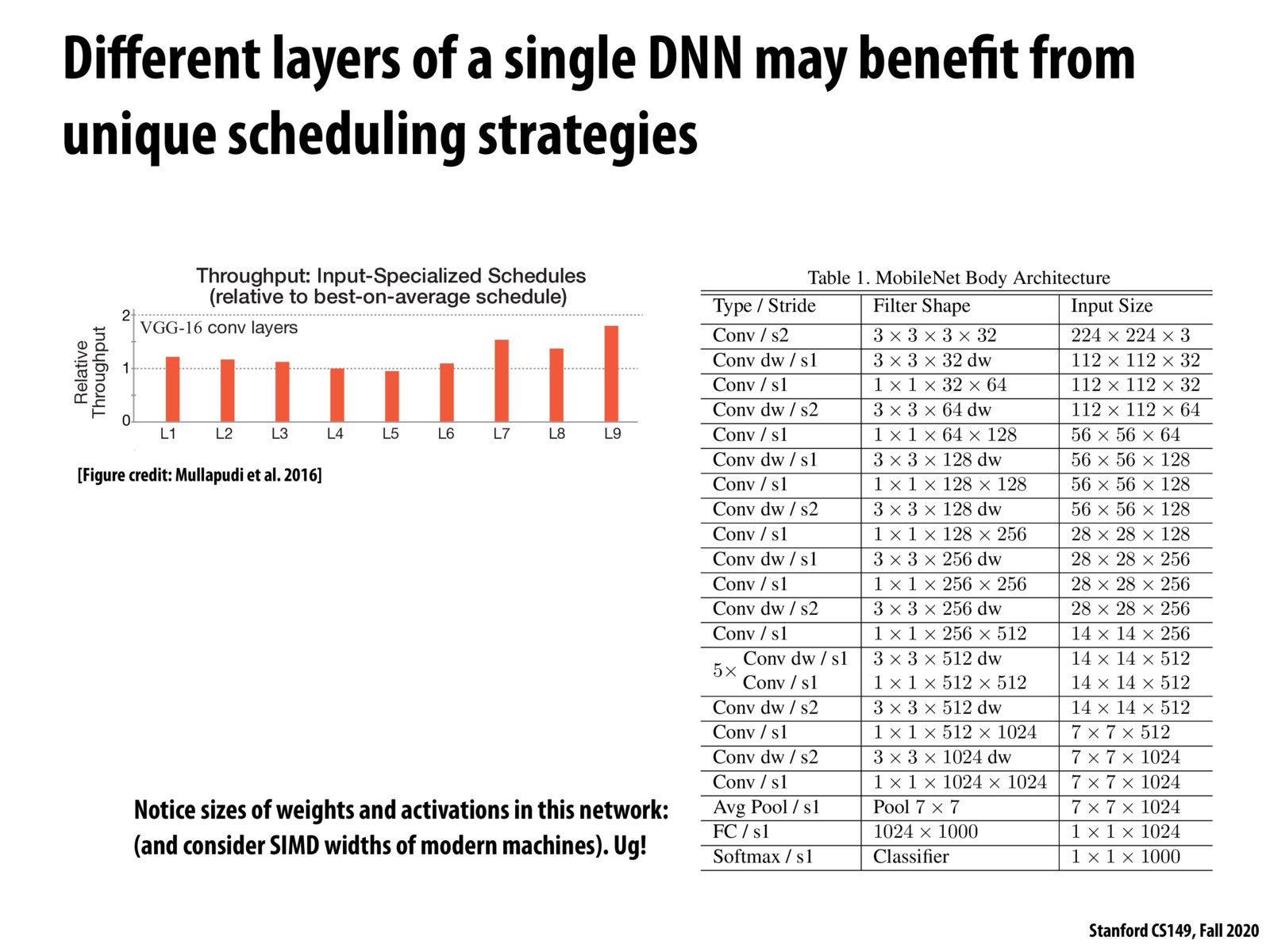
In lecture, Kayvon explained a bit more about the graph on the left. A student found that a hand-optimization for one of the layers was nearly 2x slower than ideal for other layers. The takeaway is that EACH layer may need to be hand-optimized (potentially using strategies we saw earlier in the lecture) depending on its input size/properties.
Please log in to leave a comment.
This data is based on hand optimization of various convolutions, which can be demanding and hence DSL that could automatically optimize performance provide huge convenience.