How important is hardware failure as a consideration when designing distributed systems and algorithms like this? Is hardware that prone to failure that data backups always need to exist? In particular, I'm wondering if hardware failures are a 'thing of the past' or will always affect any distributed system.
barracuda
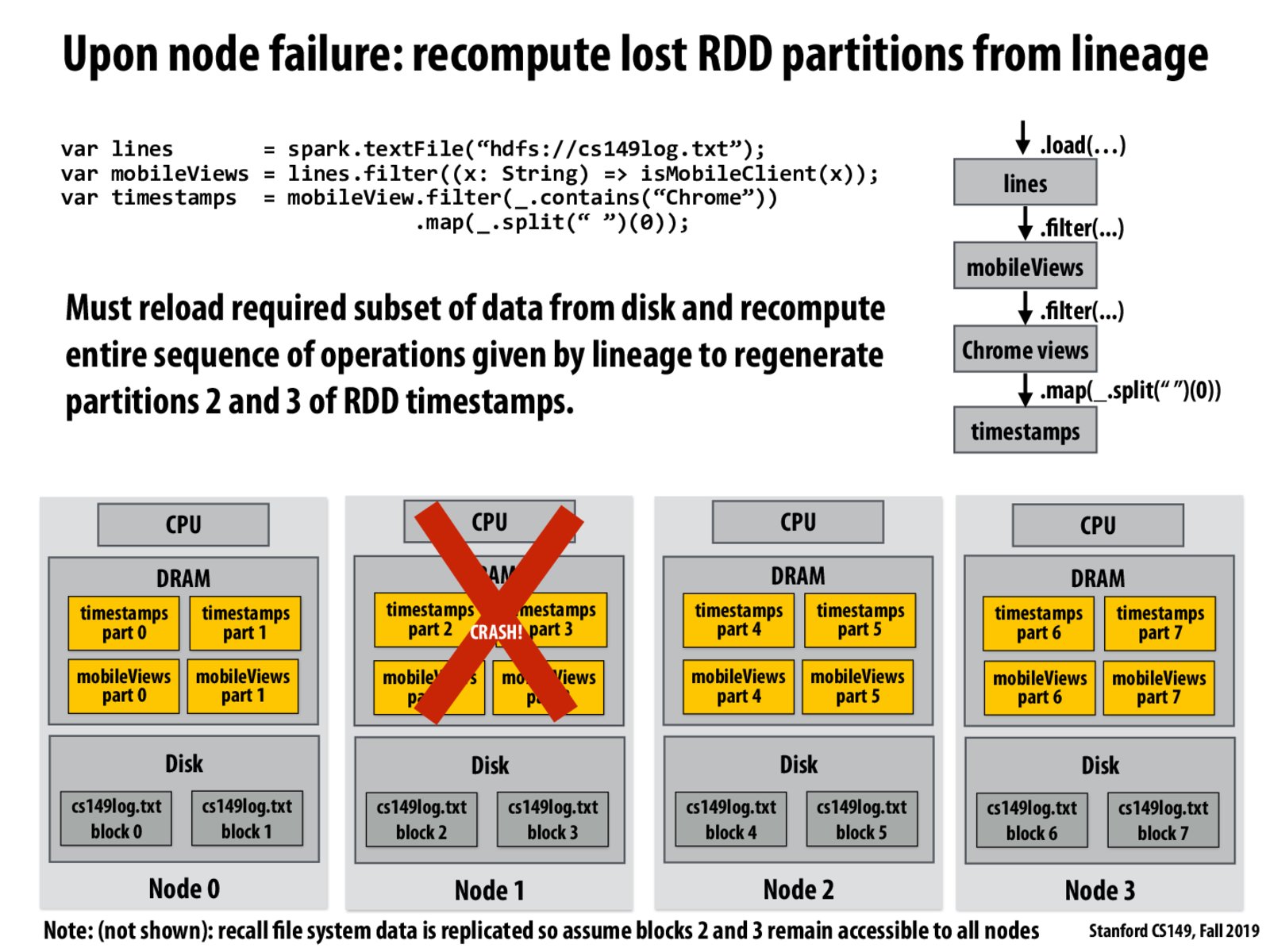
It's a big consideration. There will always be a nonzero probability of hardware failure, particularly in a distributed system of thousands of machines. Note that in this situation, fault tolerance is provided not only by Spark, but also HDFS. HDFS provides the underlying fault tolerance of the original log data by handling replication of that raw data (as alluded to in the 'Note' on the slide), while Spark provides the fault tolerance of recomputing portions of lost RDDs from a lineage.
How important is hardware failure as a consideration when designing distributed systems and algorithms like this? Is hardware that prone to failure that data backups always need to exist? In particular, I'm wondering if hardware failures are a 'thing of the past' or will always affect any distributed system.
It's a big consideration. There will always be a nonzero probability of hardware failure, particularly in a distributed system of thousands of machines. Note that in this situation, fault tolerance is provided not only by Spark, but also HDFS. HDFS provides the underlying fault tolerance of the original log data by handling replication of that raw data (as alluded to in the 'Note' on the slide), while Spark provides the fault tolerance of recomputing portions of lost RDDs from a lineage.