This suggests that the total amount of space requested on shared memory is somehow known to the scheduler beforehand so that it can tell whether a new block will fit in each of the cores. This led me to wonder what would happen if the requested space is of variable length. One pathological example would be if we want an array whose length will be a random positive number generated inside the kernel. As it turns out, this example will not be allowed; be it at compile time or at run time, the system must be able to know the exact amount of space requested when a kernel is invoked. One way to achieve this is statically declaring a space like the example we saw earlier in this slide deck. In this case, the size is known at compile time. If we want to dynamically allocate space, it turns out we need to pass the requested size as the execution configuration parameter when calling the kernel. This is an interesting design choice that makes for more efficient task scheduling!
The following link was a useful resource to understand this behavior. https://devblogs.nvidia.com/using-shared-memory-cuda-cc/
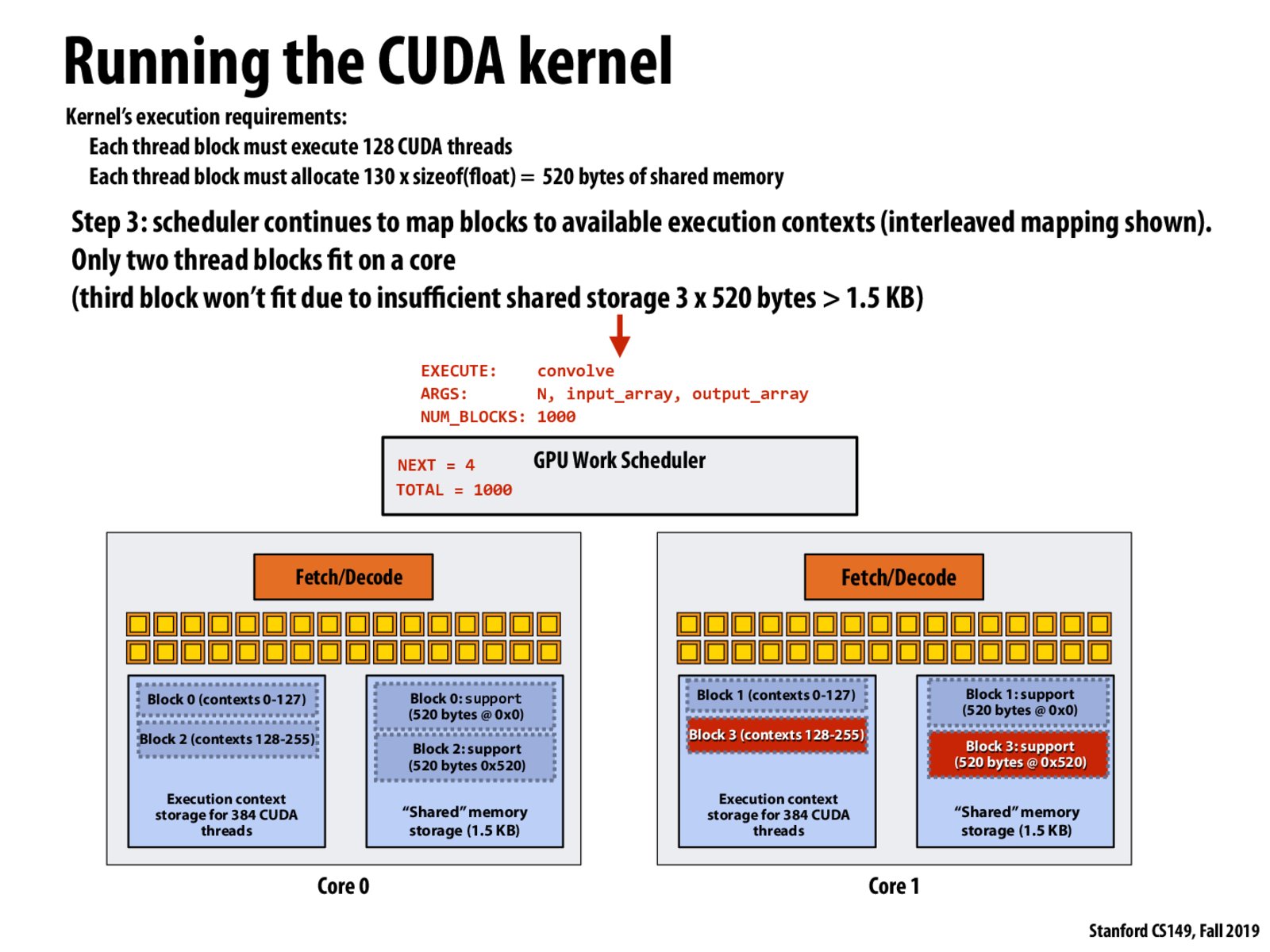
This suggests that the total amount of space requested on shared memory is somehow known to the scheduler beforehand so that it can tell whether a new block will fit in each of the cores. This led me to wonder what would happen if the requested space is of variable length. One pathological example would be if we want an array whose length will be a random positive number generated inside the kernel. As it turns out, this example will not be allowed; be it at compile time or at run time, the system must be able to know the exact amount of space requested when a kernel is invoked. One way to achieve this is statically declaring a space like the example we saw earlier in this slide deck. In this case, the size is known at compile time. If we want to dynamically allocate space, it turns out we need to pass the requested size as the execution configuration parameter when calling the kernel. This is an interesting design choice that makes for more efficient task scheduling!
The following link was a useful resource to understand this behavior. https://devblogs.nvidia.com/using-shared-memory-cuda-cc/